Tracking versions with PAV
The PAV ontology specializes the W3C PROV-O standard to give a lightweight approach to recording details about a resource, giving its Provenance, Authorship and Versioning. Our paper on PAV explores all of these aspects in details. In this blog post we discuss Versioning as modelled by PAV, including their hierarchical organization.
- Version numbers {#versionnumbers}
- Making versions retrievable {#retrievable}
- Ordering previous versions {#ordering}
- Related work {#relatedwork}
- Organize the versions {#organize}
Versioning is commonly used for software releases (e.g. Windows 8.1, Firefox 26, Python 3.3.2), but increasingly also for datasets and documents. For the purpose of provenance, a version number allows the declaration of the current state of a resource, which can be cross-checked against release notes and used for references, for instance to indicate which particular version of a dataset was used in producing an analysis report.
Versions in PAV are quite straight forward. For our working example, let’s look at the official releases of the PAV ontology itself. Note that PAV is intended for describing any kind of web resource (e.g. documents, datasets, diagrams), not just ontologies, but we’ll use this example as it allows us to explore versioning both from a document and a technical perspective.
Version numbers
So as an example, some versions of the PAV 2.x series (skipping patch versions for now):
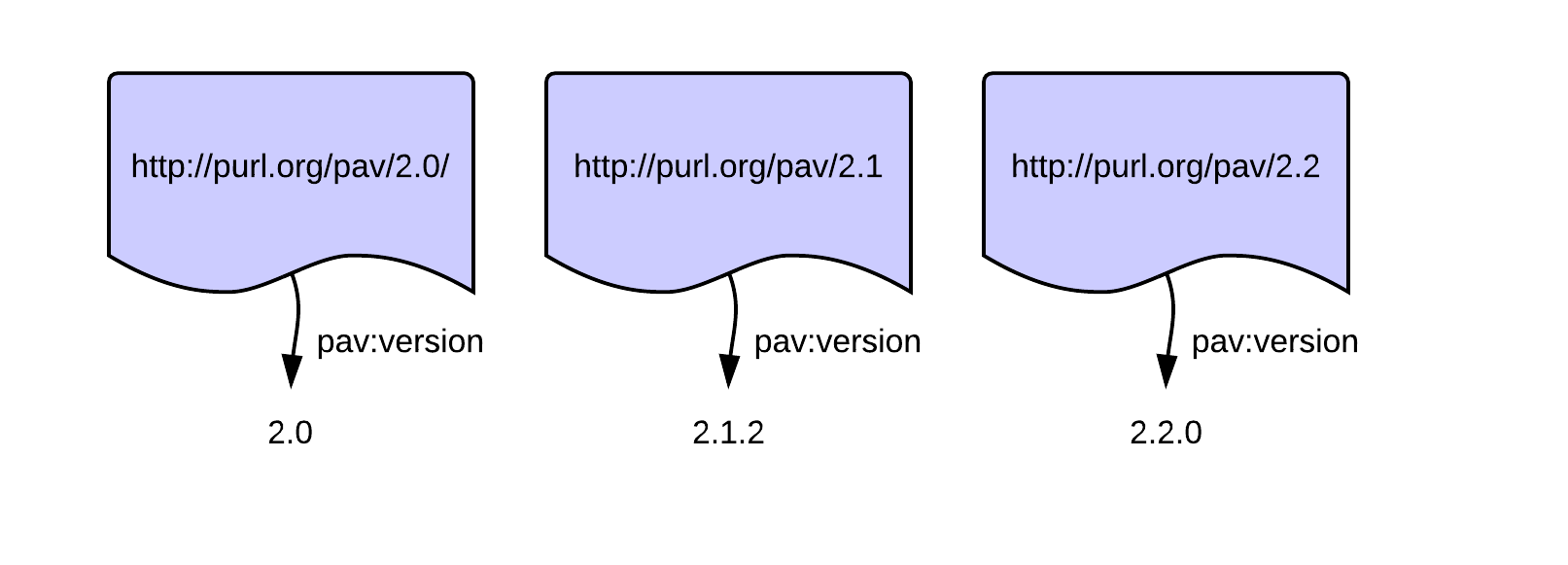
The property pav:version gives a human-readable version string. Note that there is no particular requirements on this string, we could just as well have labelled the versions “red”, “blue” and “green”.
Semantic versioning
Rather than arbitrary version strings, a numeric major.minor.patch version number following semantic versioning rules are a bit easier to understand, and come with explicit promises that help predict backward and forward compatibility. What would classify as a major/minor/patch change really depend on the nature of a resource and its role, and although these rules are written for software they also apply well to a range of resources. For instance:
- Changing the font of the Coca-Cola logo would mean a new major version, e.g. from 1.1.5 to 2.0.0
- Adding a new paragraph to a legal document means incrementing the minor version, e.g. from 2.2.1 to 2.3.0
- Fixing grammar in a chemistry lab report would increment the patch version, e.g. from 2.4.0 to 2.4.1
- Changing a single chemical symbol in a formula would however be a minor increment (changing the reaction), e.g. from 2.4.1 to 2.5.0
- In software, adding a new function to an API or a new command line option means incrementing the minor version, e.g. from 2.5.0 to 2.6.0
- For a web mail service, removing the “Reply To All” button would be a new major version (removes functionality), e.g. from 2.6.0 to 3.0.0
- Removing a column from a dataset would usually mean incrementing the major version (as this could break functionality for anyone depending on that column), e.g. from 3.5.1 to 4.0.0
- Adding more rows would be a minor change (as it would scientifically speaking be an updated dataset), e.g from 4.0.0 to 4.1.0
- Fixing a particular cell that was wrongly formatted as a number rather than a date would just be a patch change, e.g. from 4.1.0 to 4.1.1
Many resources such as a regular home page or an Excel spreadsheet of expenses does not have any formal versioning process, and probably won’t really benefit much from semantic versioning, in which case the best options would often be increasing numbers (“19”, “20”, “21”) or ISO-8601 date/time stamps (“2013-12-24”, “2013-12-28”, “2014-01-02 15:04:01Z”) – both which can easily be generated by software without needing any understanding of the nature of the change.
Making versions retrievable
In the figure above, each versioned resource have their own URI to allow you to retrieve that particular version. Although there is no requirement for such availability, it can be quite beneficial for several reasons, particularly combined with semantic versioning. For instance, the way we have deployed our ontology means that if you wanted to use PAV version 2.1 without any terms introduced in 2.2 or later, then you can use http://purl.org/pav/2.1 to consistently download (or programmatically import) the ontology as it was in version 2.1.
(Side note: We deliberately have not versioned the PAV namespace, so pav:version expands to http://purl.org/pav/version no matter which ontology version was loaded. To avoid misunderstandings such as http://purl.org/pav/2.0/version we removed the trailing / in the version URI from 2.1 onwards).
Ordering previous versions
Now, a computer seeing these three resources would not know they are ordered 2.0, 2.1, 2.2, or not even that they are related at all. With PAV we can add the pav:previousVersion property:

Note how pav:previousVersion goes directly between the resources, in PAV the ‘previous version’ is not a free standing tag separate from the resource, but an actual copy or snapshot of the versioned resource as it was in that state. This eventually forms a chain of versioned resources, here providing the lineage of version 2.3 through 2.2 and 2.1 to 2.0.
In PAV, pav:previousVersion is meant to be used as a functional property (pointing at a single resource); this means that for any given resource, only the exactly previous version is stated directly, to find any earlier versions you can follow the chain.
In the picture above I have pencilled in a PAV version 2.3 as a draft, to highlight that pav:previousVersion is purely a way to show the version lineage from a given resource, and not as prescribing as dcterms:replaces, which specifies a related resource that is supplanted, displaced, or superseded by the described resource. The authority of when a resource is ready to supersede its previous version is often separate from its version lineage. We’ll come back to the “current version” later in this blog post.
Note that since making this figure, PAV 2.3 has actually been released. 😊
Providing provenance for each version
One advantage of having each versioned resource explicit, beyond being able to retrieve them, is that you can attach additional properties, reflecting the state of each version. For instance, for a dataset, each version can have its own provenance of how they had been prepared:
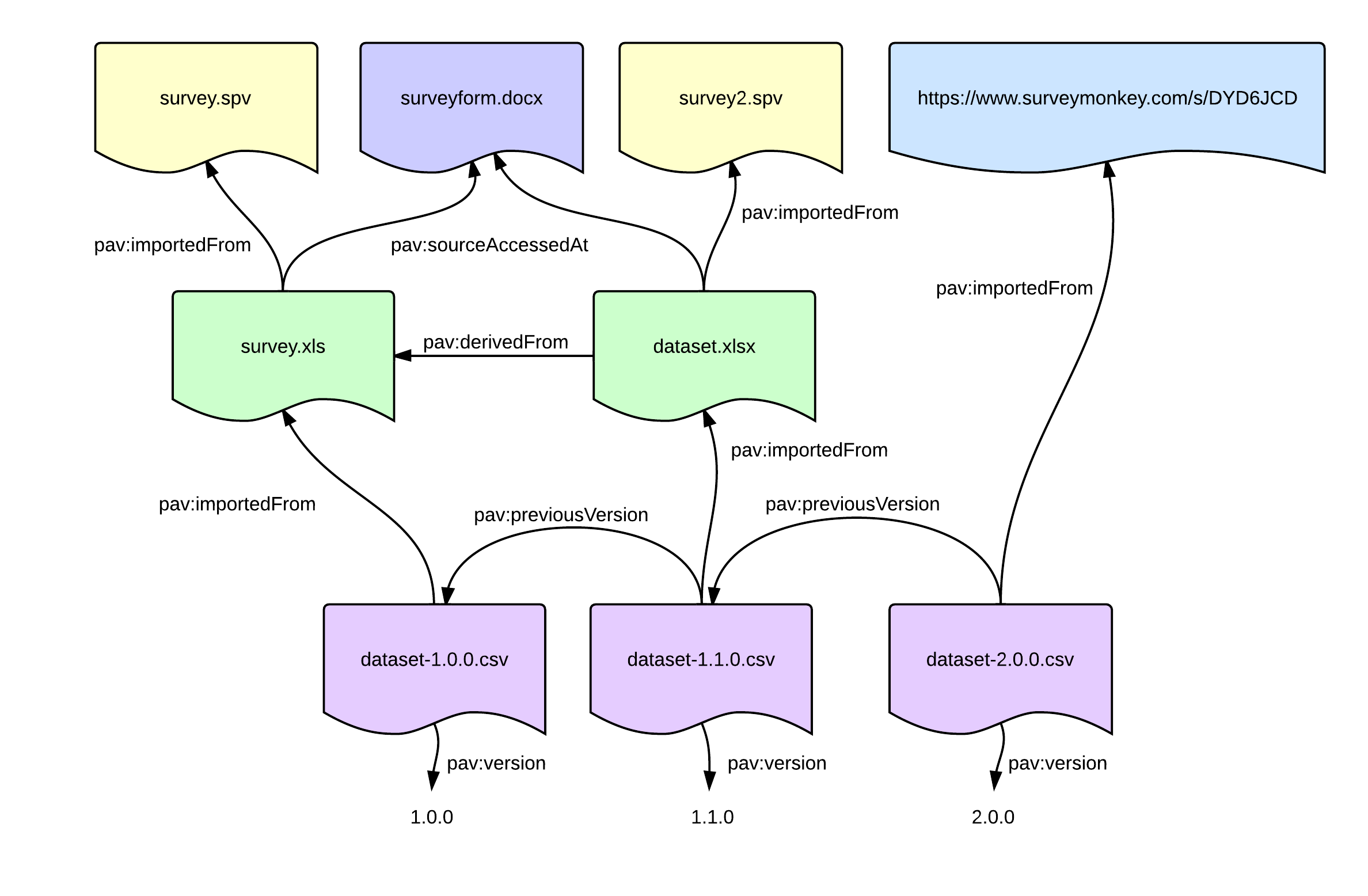
Example of using PAV to version datasets, showing the provenance of each individual version. doi:10.6084/m9.figshare.894329
In this example, dataset-1.0.0.csv has been pav:importedFrom survey.xls, i.e. probably saved from Excel (the software can be specified using pav:createdWith). The Excel file was imported from an SPSS survey data file, but in addition had a pav:sourceAccessedAt the survey form (e.g. the creator looked up more descriptive column headers).
For dataset-1.1.0.csv we (as humans) can see the minor version has been incremented, and that it has a different provenance, this version was imported from dataset.xlsx, which has been pav:derivedFrom the earlier survey.xls (indicating that the spreadsheet have evolved significantly). The data was imported from a different survey2.spv (which might or might not be related to survey.spv), but still accessed the same surveyform.docx.
For dataset-2.0.0.csv the provenance is quite different, this time the scientist has simply used Survey Monkey rather than SPSS to manage their survey, and have simply published its exported CSV. Presumably this dataset is quite different in its structure, as it has gained a new major version to become 2.0.0. Note that if the content of the dataset (its knowledge) had significantly changed, e.g the old dataset showed baby birth weights while the next dataset was a survey of pregnant mothers, their education levels and their baby’s birth weight, then the new dataset should rather be related with pav:derivedFrom.
Adding other PAV properties to relate agents to versions, such as pav:createdBy, pav:importedBy and pav:authoredBy, can be useful particularly to attribute different people involved with each release.
Related work
While we have presented versioning with PAV, other vocabularies exists with alternative ways to model versions.
PROV-O revisions
In the W3C specification PROV-O, the term prov:wasRevisionOf can be used to relate versions:
A revision is a derivation for which the resulting entity is a revised version of some original. The implication here is that the resulting entity contains substantial content from the original. Revision is a particular case of derivation.
While at first prov:wasRevisionOf seem to achieve the same as pav:previousVersion, the PROV definition is focusing on revision as a form of derivation. As the dataset example above showed, versions are not necessarily related through simple derivations, but can have their own provenance. It is unclear if prov:wasRevisionOf also might be used to give shortcuts to older versions, while pav:previousVersion only should be used towards the directly previous version. The PAV property also recommends giving the human-readable pav:version.
We do however acknowledge that most common use of prov:wasRevisionOf is very similar to pav:previousVersion, and have therefore mapped pav:previousVersion as a subproperty of prov:wasRevisionOf. Although this also indirectly means a PAV previous version is related with a PROV derivation, the definition of prov:wasDerivedFrom is intentionally quite wide and should also cover pav:previousVersion as an ‘update’:
A derivation is a transformation of an entity into another, an update of an entity resulting in a new one, or the construction of a new entity based on a pre-existing entity.
Our derivation subproperty pav:derivedFrom is again intentionally more specific, requiring a significant change in content, and thus can be used to clarify the level of change.
We made a mapping to PROV-O which explains the rationale for each PAV subproperty.
Qualified revisions
One interesting aspect of PROV-O is the ability to qualify relations. prov:wasRevisionOf (and therefore also pav:previousVersion) can be qualified using prov:qualifiedRevision. For instance we could expand the relation between dataset 2.0.0 and 1.1.0 to explain why we had to change the major version:
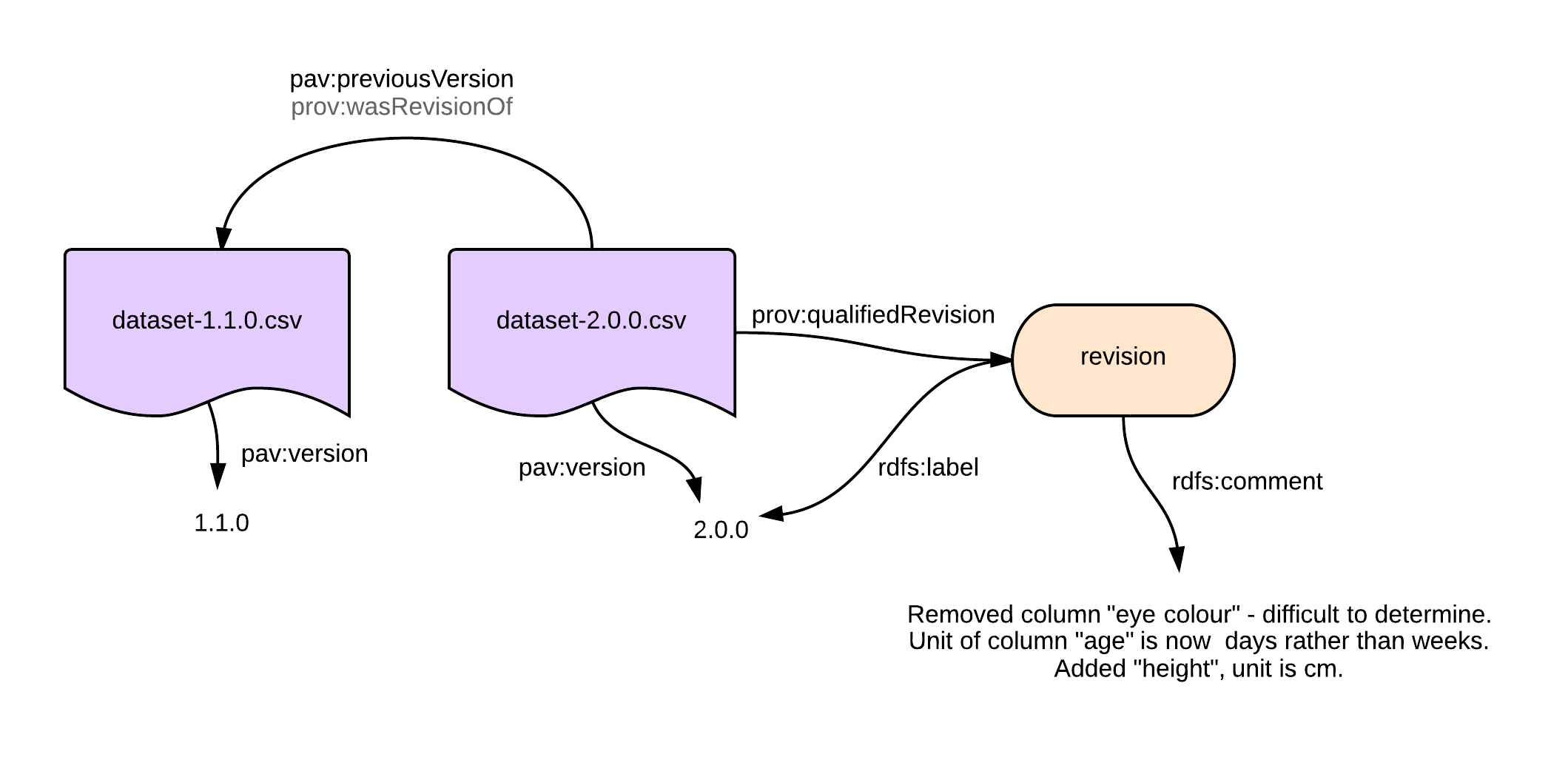
prov:qualifiedRevision can be used to detail pav:previousVersion, here explaining the changes of the dataset using rdfs:comment. Note that this figure does not show the qualified link prov:entity from the revision to dataset-1.1.0.csv.
Note that it will often be difficult to assign a retrievable URI for the revision itself, unless some kind of versioning system (like Github or Google Code) provides a way to link to the change or revision itself.
This kind of qualification pattern can be also be used for other PAV properties that have PROV superproperties, such as prov:qualifiedDerivation on pav:importedFrom, or prov:qualifiedAttribution on pav:authoredBy, however in many cases it might be better to expand the change by relating entities to PROV activities.
DC Terms
The Dublin Core Terms is a well-established and popular vocabulary to provide bibliographic records, particularly for document-like resources. As its focus is on human-readable bibliographies rather than provenance, there is not necessarily a ‘backwards in time’ lineage when using DC Terms relations. These DC Terms properties can be used for describing versions of resources:
- dcterms:replaces – A related resource that is supplanted, displaced, or superseded by the described resource. As mentioned before, this is similar to pav:previousVersion, but adds a stamp of authority as the older version is superseded or displaced. So for instance if our dataset-2.0.0.csv was experimental and not really a good replacement for 1.1.0 (say we really wanted to include eye colour), then
dcterms:replaceswould not be appropriate until there was a new “official version” – which might not be until 2.1.3. The inverse, dcterms:isReplacedBy, can be used as a forward pointing property to indicate that a resource is no longer current. - dcterms:isVersionOf – A related resource of which the described resource is a version, edition, or adaptation. Changes in version imply substantive changes in content rather than differences in format. This property is quite wide, in that it could cover any kind of adaptation, like the Romeo+Juliet movie being a version of the Shakespeare theatre play Romeo and Juliet.
In provenance term, such adaptions are normally covered byprov:wasDerivedFrom(the movie was based on the theatre play) or prov:alternateOf (the movie as an alternate of a theatre performance), while differences in abstraction levels (e.g. the DVD vs. the movie in general) are covered with prov:specializationOf and FRBR-like abstraction models. Additionally,pav:previousVersiondoes not normally cover substantive changes in content, that should be described usingpav:derivedFrom. - dcterms:hasVersion – A related resource that is a version, edition, or adaptation of the described resource. This is the inverse of
dcterms:isVersionOf, but also suffers from sometimes being used as a kind ofprov:qualifiedRevisionpointing at a free-standing revision resource (as in our dataset example above), or as a more hierarchical unversioned-to-versioned relationship (prov:generatizationOf). Even within the DC Terms history there seems to be a confusing mix ofdcterms:hasVersionanddcterms:replacesthat hints of hierarchical use, but also makes a resources have themselves as versions.
PAV has a mapping to DC Terms (available as SKOS) which explains how the two vocabularies could be aligned, however we have not included the versioning part of this mapping in the formal OWL ontology due to the above reasons.
schema.org
schema.org is a set of terms that has grown to be amongst the most popular vocabularies for describing web resources, partially because of its usage by Google, Yahoo and Bing. Terms we identified to be related to versioning are:
- schema:version – The version of the CreativeWork embodied by a specified resource. This can be seen as a more specific version of pav:version, the biggest difference is that
schema:versionis typed to be aschema:Number, and so might not cover versions like “1.5.2” or “2014-01-05”. - schema:isBasedOnUrl – A resource that was used in the creation of this resource. This term can be repeated for multiple sources. This is more of a loose provenance term which could be seen to cover all of
pav:sourceAccessedAt, pav:importedFrom, pav:retrievedFrom,prov:wasDerivedFromand prov:wasInfluencedBy. - schema:successorOf – A pointer from a newer variant of a product to its previous, often discontinued predecessor. While this description is similar to
pav:previousVersionand dcterms:replaces, the term seem to only be used from/to schema:ProductModels which would not cover web resources that are not product sheets. The same applies to its inverse schema:predecessorOf. - schema:isVariantOf – A pointer to a base product from which this product is a variant. It is safe to infer that the variant inherits all product features from the base model, unless defined locally. This property, also only used from/to
schema:ProductModel, is a specialization of dcterms:isVersionOf and prov:specializationOf.
Organize the versions
In PAV 2.3 we added three additional properties for versioning:
Earlier versions
pav:hasEarlierVersion point to any earlier version, not just the directly previous version. This is a transitive super-property of pav:previousVersion, which means you can build a linear chain of previous versions, and imply all the earlier versions. (Importantly pav:previousVersion is NOT transitive). For simplicity there is no inverse property for the later version – as we think an earlier version shouldn’t make “future” declarations, rather the newer version should indicate its earlier version (following the direction of provenance).
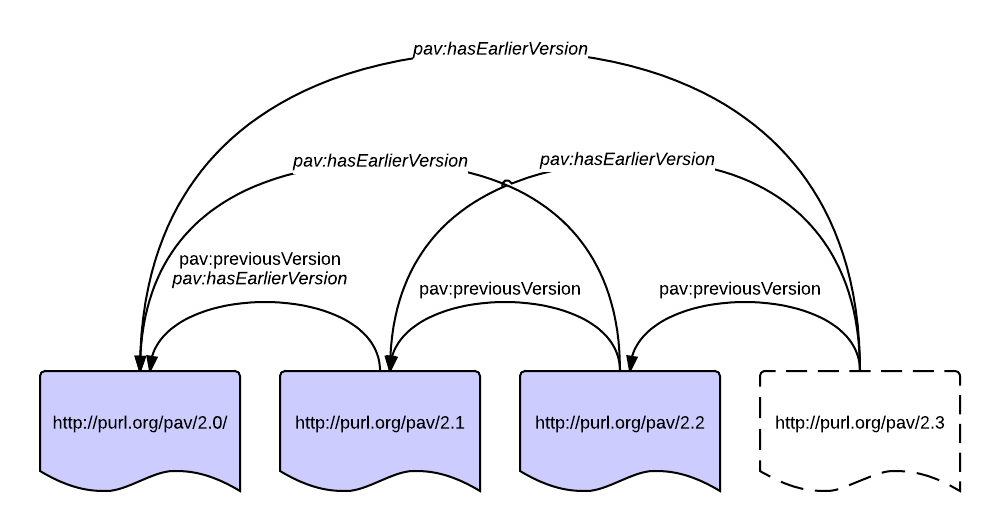
Has a version (snapshots)
pav:hasVersion is a specialization of dcterms:hasVersion – which formalizes that this property is for hierarchical versioning:
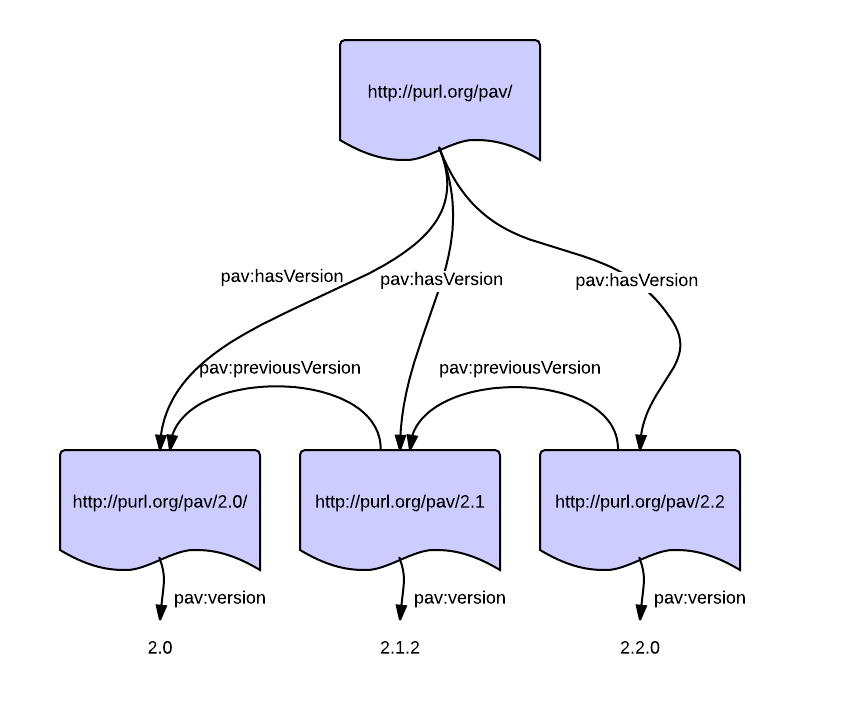
This shows how http://purl.org/pav/ is a more general entity that spans across the multiple snapshots, therefore pav:hasVersion is also a subproperty of prov:generalizationOf – indicating the hierarchical nature of the entities describing the same thing with different (time) characteristics.
Note that unlike dcterms:hasVersion, pav:hasVersion goes to a snapshot – the version should be retrievable at its URI, so it would usually not be good taste to use pav:hasVersion to a revision info page that does not include the page as it was in that version.
However for Software Releases, using GitHub release pages as versions is probably a good idea.
Current version
While these snapshots should contain pav:previousVersion between them to provide a version lineage, it is often useful to declare what is the current version. So we have also pav:hasCurrentVersion:
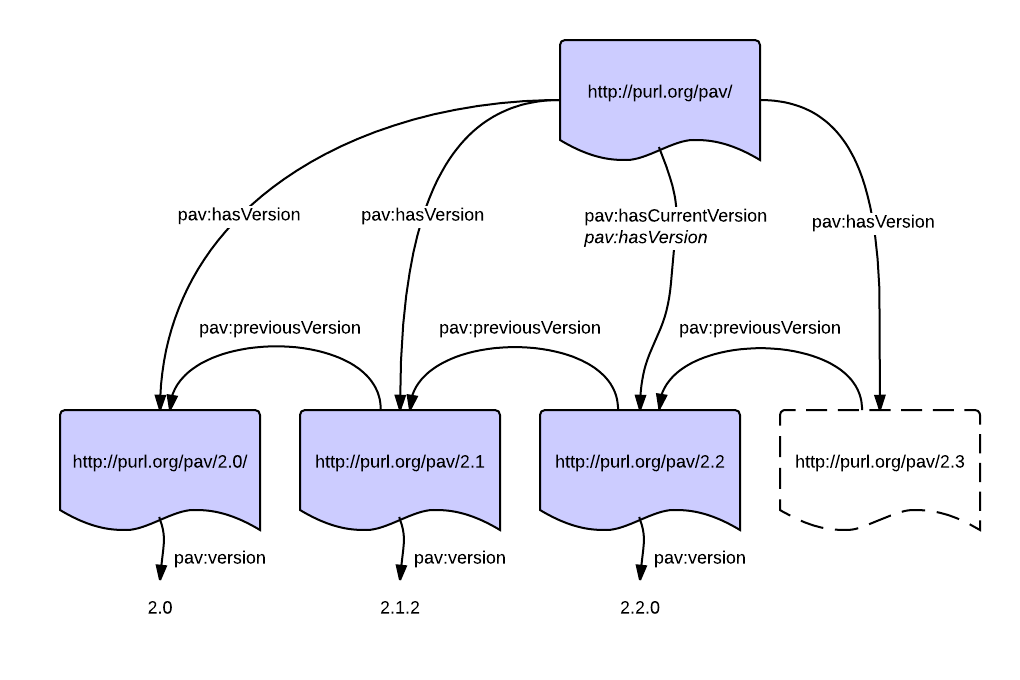
Thus pav:hasCurrentVersion is useful to provide a permalink for a dynamic page. Often this is what people have meant with a more functional use dcterms:hasVersion – pointing to a single current snapshot – where older snapshots would have dcterms:isVersionOf backlinks. While that pattern might have been used, it is not formally defined as such by DC Terms.
As pav:hasCurrentVersion specializes pav:hasVersion you don’t need to duplicate that relation for the current version. Note that the current version is not necessarily the latest version – there could be a newer version (e.g. a draft or release candidate) which is not yet official – as exemplified above with PAV 2.3 as a draft. (Note that since making this figure PAV 2.3.1 has been released)
Here we can see that there’s a “future” PAV version that may or may not later become the pav:hasCurrentVersion (it is infact now the current version).This is typical of software development, where you often have alpha versions and release candidates.
It can be useful to have third-party “versions” (e.g. forks in software development) – where you could not find the official pav:hasVersion statement from the upstream repository. In this case you should add a prov:specializationOf backlink and pav:derivedFrom statement to which version you forked.
Hierarchies all the way down
There is nothing preventing you from also using pav:hasVersion to define deeper hierarchies, e.g. for software using semantic versioning:
<http://purl.org/pav/> pav:hasVersion
<http://purl.org/pav/1>,
<http://purl.org/pav/2> .
<http://purl.org/pav/2> pav:hasVersion
<http://purl.org/pav/2.0>,
<http://purl.org/pav/2.1>,
<http://purl.org/pav/2.2>,
<http://purl.org/pav/2.3> .
<http://purl.org/pav/2.3> pav:hasVersion
<http://purl.org/pav/2.3.0>
<http://purl.org/pav/2.3.1> .
<http://purl.org/pav/2.2> pav:hasVersion
<http://purl.org/pav/2.2.0> .
<http://purl.org/pav/2.1> pav:hasVersion
<http://purl.org/pav/2.1.0>,
<http://purl.org/pav/2.1.1>,
<http://purl.org/pav/2.1.2> .
But this raises some challenges with pav:previousVersion, pav:hasCurrentVersion and pav:version.
I would suggest this pattern for representing semantic versioning hierarchically:
<http://software.example.com/> pav:hasCurrentVersion <http://software.example.com/v2.1.0> ;
pav:version "2.1.0" .
<http://software.example.com/v2> pav:hasCurrentVersion <http://software.example.com/v2.1.0> ;
pav:previousVersion <http://software.example.com/v1> ;
pav:version "2.1.0" .
<http://software.example.com/v2.1> pav:hasCurrentVersion <http://software.example.com/v2.1.0> ;
pav:previousVersion <http://software.example.com/v2.0> ;
pav:version "2.1.0" .
<http://software.example.com/v2.1.0> pav:version "2.1.0" ;
pav:previousVersion <http://software.example.com/v2.0.1> .
.. as pav:hasCurrentVersion should point to the permalink snapshot in a functional way, it would be confusing to also include its “current version” as "2" and "2.1". So I suggest to let it always point to the “deepest” version. pav:version of the intermediaries should show the latest version of their pav:hasCurrentVersion – not a generic "2" or "2.1". (You can use rdfs:label to say "2.1").
For the ‘abandoned’ versions, pav:hasCurrentVersion and pav:version would be the latest one within their level:
<http://software.example.com/v2.0> pav:hasCurrentVersion <http://software.example.com/v2.0.1> ;
pav:previousVersion <http://software.example.com/v1.2> ;
pav:version "2.0.1" .
<http://software.example.com/v2.0.0> pav:version "2.0.1" ;
pav:previousVersion <http://software.example.com/v2.0.0> .
<http://software.example.com/v2.0.0> pav:version "2.0.0" ;
pav:previousVersion <http://software.example.com/v1.2.3> .
Note that software often have patch updates at “older” maintenance branches – e.g. it could be that the current 1.2 version is 1.2.9 even though v2.0.0 was derived from 1.2.3.
If you want to describe merges across these branches, then you would probably need to add additional pav:derivedFrom statements.