The Specimen Data Refinery: A canonical workflow framework and FAIR Digital Object approach to speeding up digital mobilisation of natural history collections
Cite as
Alex Hardisty, Paul Brack, Carole Goble, Laurence Livermore, Ben Scott, Quentin Groom, Stuart Owen, Stian Soiland-Reyes (2022):
The Specimen Data Refinery: A canonical workflow framework and FAIR Digital Object approach to speeding up digital mobilisation of natural history collections.
Data Intelligence 4(2)
https://doi.org/10.1162/dint_a_00134
License and modifications
- License: Creative Commons Attribution License (CC BY 4.0).
- Modifications: Formatting as Markdown; figures replaced with higher resolutions from source; figure caption formatting; references in s11 house style; added DOIs and URLs; cited preprints replaced with later publications; inline citation hyperlinks.
The Specimen Data Refinery
A canonical workflow framework and FAIR Digital Object approach to speeding up digital mobilisation of natural history collections
Alex Hardisty1, Paul Brack2, Carole Goble2, Laurence Livermore3, Ben Scott3, Quentin Groom4, Stuart Owen2, Stian Soiland-Reyes2,5
1School of Computer Science and Informatics, Cardiff University, Cardiff CF24 3AA, Cardiff, UK
2The Department of Computer Science, The University of Manchester, Manchester, UK
3The Natural History Museum, London, London, SW7 5BD, UK
4Meise Botanic Garden, Nieuwelaan 38, 1860 Meise, BE
5Informatics Institute, Faculty of Science, University of Amsterdam, NL
Abstract
A key limiting factor in organising and using information from physical specimens curated in natural science collections is making that information computable, with institutional digitization tending to focus more on imaging the specimens themselves than on efficiently capturing computable data about them. Label data are traditionally manually transcribed today with high cost and low throughput, rendering such a task constrained for many collection-holding institutions at current funding levels.
We show how computer vision, optical character recognition, handwriting recognition, named entity recognition and language translation technologies can be implemented into canonical workflow component libraries with findable, accessible, interoperable, and reusable (FAIR) characteristics. These libraries are being developed in a cloud-based workflow platform – the ‘Specimen Data Refinery’ (SDR) – founded on Galaxy workflow engine, Common Workflow Language, Research Object Crates (RO-Crate) and WorkflowHub technologies. The SDR can be applied to specimens’ labels and other artefacts, offering the prospect of greatly accelerated and more accurate data capture in computable form.
Two kinds of FAIR Digital Objects (FDO) are created by packaging outputs of SDR workflows and workflow components as digital objects with metadata, a persistent identifier, and a specific type definition. The first kind of FDO are computable Digital Specimen (DS) objects that can be consumed/produced by workflows, and other applications. A single DS is the input data structure submitted to a workflow that is modified by each workflow component in turn to produce a refined DS at the end. The Specimen Data Refinery provides a library of such components that can be used individually, or in series. To cofunction, each library component describes the fields it requires from the DS and the fields it will in turn populate or enrich. The second kind of FDO, RO-Crates gather and archive the diverse set of digital and real-world resources, configurations, and actions (the provenance) contributing to a unit of research work, allowing that work to be faithfully recorded and reproduced.
Here we describe the Specimen Data Refinery with its motivating requirements, focusing on what is essential in the creation of canonical workflow component libraries and its conformance with the requirements of an emerging FDO Core Specification being developed by the FDO Forum.
Introduction
A key limiting factor in organising and using information from physical specimens curated in natural history collections is making that information computable (‘machine-actionable’) and extendable. More than 85% of available information currently resides on labels attached to specimens or in physical ledgers [Walton 2020a]. Label data are commonly transcribed manually with high cost and low throughput, rendering such a task constraining for many institutions at current funding levels. However, the advent of rapid, high-quality digital imaging has meant that digitizing specimens, including their labels, is now faster and cheaper [Thiers 2016]. With initiatives such as Advancing Digitization of Biological Collections (ADBC), integrated Digitized Biocollections (iDigBio) and the Distributed System of Scientific Collections (DiSSCo) [Nelson 2019a, Nelson 2019b, Addink 2019, Lannom 2020] aiming to increase the rate and accuracy of both mass and on-demand digitization of natural history collections, the gap between expectations of what should be digitally available and computable, and what can be achieved using traditional transcription approaches is widening. Modern, highly efficient workflow tools and approaches can play a role to address this.
Collection digitization began towards the end of the 20th century by typing basic data from labels into the collection (asset) management systems of collection-holding institutions such as natural history museums, herbaria and universities. Initially, this was to facilitate indexing and cataloguing and locating the physical specimens, but with the addition of photographic images of specimens and the public availability of specimen data records, through data portals of the institutions themselves as well as international data infrastructures like the Global Biodiversity Information Facility (GBIF), such bodies of data have been rapidly exploited for research [GBIF 2021, Heberling 2021]. It has become clear that widespread digitization of data about physical specimens in collections and the advent of high-throughput digitization processes [Sweeney 2018, Allan 2019, Hereld 2019, Price 2018, Tegelberg 2017] is transforming and will radically further transform the range of scientific research opportunities and questions that can be addressed [Heberling 2019, Kharouba 2019]. Scientific conclusions and policy decisions evidenced by digital specimen data enhance humankind’s ability to conserve, protect, and predict the biodiversity of our world [Watanabe 2019, Lughadha 2019].
Harnessing technologies developed to harvest, organise, analyse and enhance information from sources such as scholarly literature, third-party databases, data aggregators, data linkage services and geocoders and reapplying these approaches to specimens’ labels and other artefacts offers the prospect of greatly accelerated data capture in a computable form [Owen 2020]. Tools of particular interest span the fields of computer vision, optical character recognition, handwriting recognition, named entity recognition and language translation.
Workflow technologies from the ELIXIR Research Infrastructure [Harrow 2021], including Galaxy [Afgan 2018], Common Workflow Language [Crusoe 2022], Research Object Crates (RO-Crates) [Ó Carragáin 2019a, Soiland-Reyes 2022a] and WorkflowHub [Goble 2021], and selected tools are integrated in a cloud-based workflow platform for natural history specimens – the ‘Specimen Data Refinery’ [Walton 2020a] that will become one of the main services to be offered by the planned DiSSCo research infrastructure [Addink 2019]. The tools themselves, implemented with findable, accessible, interoperable, and reusable (FAIR) characteristics [Wilkinson 2016] are packaged into canonical workflow component libraries [Wittenburg 2022b], rendering them reusable, and interoperable with one another. FAIR Digital Objects are adopted as the common input/output pattern, fully compatible with digital objects at the core of DiSSCo data management [Hardisty 2019b].
The Refinery brings together domain-specific workflows for processing specimen images and extracting text and data from images with canonical forms for components and interactions between components that can lead to improved FAIR characteristics for both the workflows themselves and the data resulting from workflow execution.
FAIR Digital Objects (FDO) are created by packaging outputs of workflows and workflow components as digital objects with metadata, a persistent identifier, and a specific type definition against which operations can be executed [De Smedt 2020]. The Refinery uses two kinds of FDOs:
-
Computable Digital Specimen (DS) objects [Hardisty 2020] from DISSCo for the scientific input/output data that can be consumed/produced by workflows and other applications.
-
Workflow objects, implemented as RO-Crates [Soiland-Reyes 2022a], from ELIXIR gather and archive the diverse set of workflow process data – the digital and real-world resources, configurations and actions (the provenance) contributing to a unit of digitization or other work producing the Digital Specimen digital objects, allowing that work to be scrutinised and faithfully reproduced if necessary.
We first summarise related work before describing the problem to be addressed by the Specimen Data Refinery. We then explain our Canonical Workflows for Research (CWFR) approach using these FDOs in the design of the SDR, the experimental setup, and results so far from the work in progress. While future work will clarify full results and challenges of implementing a robust, reliable, and easy-to-use production-capability SDR, in this early report following SDR prototyping and conceptualization, we focus on what we found to be essential in the use of FDOs and CWFR canonical step libraries, and on the compliance of canonical workflow (component) inputs and outputs with the requirements of the FDO Framework [Bonino 2019].
Related Work
Workflows for processing specimen images and extracting data
While natural history collections are heterogeneous in size and shape, often they are mass digitized using standardised workflows [Sweeney 2018, Allan 2019, Hereld 2019, Price 2018, Tegelberg 2017]. In pursuit of higher throughput at lower cost, yet with higher accuracy and richer metadata, further automation will increasingly rely on techniques of object detection and segmentation, optical character recognition (OCR) and semantic processing of labels, and automated taxonomic identification and visual feature analysis [Walton 2020a, Owen 2020].
Although there is a great deal of variety among images of different kinds of collection objects that are digitized (see Figure 1) there are visual similarities between them. Most images contain labels, scale bars and often, colour charts as well as the specimen itself. This makes them amenable to improved approaches to object detection [Triki 2020] and segmentation into ‘regions of interest’ [Nieva de la Hidalga 2021] as precursive steps for multiple kinds of workflows.

A range of specimen images
From the Natural History Museum, London, demonstrating the diversity of collection objects, which include handwritten, typed, and printed labels. (a) Microscope slide (NHMUK010671647), (b) Herbarium specimen (BM000546829), (c) pinned insect (NHMUK013383979)
Segmentation, specifically, can be employed as an early step in a workflow to send just the relevant region(s) of interest from an image to later workflow steps. Not only does this decrease data transfer time and minimise computational overheads but it can also substantially increase the accuracy of subsequent OCR processing and semantic recognition steps [Owen 2020].
Much of the data about specimens is stored on their handwritten, typed or printed labels or in registers/ledgers [Walton 2020b]. Direct manual transcription into local databases with manual georeferencing is the primary method used today to capture this data. Potentially, OCR can significantly increase transcription speeds whilst reducing cost; although it sacrifices accuracy and disambiguation that are today achieved with specialist knowledge provided by humans during the process. Returning character strings from OCR is useful, but semantically placing this data in its context as information specific to natural history specimens and linking that back to the original physical specimens is of much higher value, improving the utility of natural history collections. Shortfalls in accuracy and disambiguation can be made up by exploiting Natural Language Processing (NLP) advances such as named entity recognition to identify text segments belonging to predefined categories (for example, species name, collector, locality, date) [Owen 2020]. Nevertheless, this only works well on a small proportion of captured data in the absence of ‘human in the loop’ input. To better automate disambiguation of people’s names, for example, access to other contextual ‘helper’ data are needed (e.g., biographical data in Wikidata) as well as cross-comparison with other data from the specimen, such as the date of collection and location [Groom 2020].
Automated identification of species from images of living organisms has achieved impressive levels of accuracy [Knyshov 2021, Hussein 2021, Carranza-Rojas 2017, Little 2020, Pryer 2022, Unger 2016] with techniques translated to an increasing range of enthusiastically received consumer applications for plant and animal identification using mobile phones (e.g., Plantsnap, PictureThis, iNaturalist SEEK). Automated identification of preserved specimens, however, presents different challenges. Although identification might be made more accurately because a specimen is presented in a standard manner, separated from other organisms and the complexity of a natural background, the loss of colour and distortion of the shape of the organism arising from preparation and preservation processes can lead to the loss of important identification clues that might be present on a living example.
Workflow management systems and canonical workflows for research
A workflow chains together atomised and executable components with the relationships between them to clearly define a control flow and a data flow. Their significant defining characteristics are (i) abstraction, through the separation of the workflow specification (the work to be done) from its execution (how it is done), and (ii) composition whereby the components can be cleanly combined and reused and workflows themselves can be neatly packaged as components [Atkinson 2017]. Workflow management systems typically provide the necessary mechanisms for explicitly defining workflows in a reusable way together with a workflow engine that executes the workflow steps and keeps an accountable record of the processing – logging the codes executed and the data lineage of the results. In the past decade there has been a rise in popularity in both the development of WfMS and their use, driven by the increasing scales of data and the accompanying complexity of its processing [Atkinson 2017].
Workflow management systems typically vary in the features they provide for supporting: workflow programming language and control flow expressivity; data type management; code wrapping, containerisation and integration with software management tools; exploitation of computational architectures; availability of development and logging tools; licensing and so on. Although several hundred kinds of such systems exist [Amstutz 2022], communities tend to cluster around a few popular systems based on their “plugged-in” availability of data type specialist codes, the catered-for skills level of the workflow developers, and its documentation, community support and perceived sustainability. For the Specimen Data Refinery, the Galaxy workflow system [Afgan 2018] in conjunction with Common Workflow Language (CWL) [Crusoe 2022] has been chosen. CWL is a workflow specification standard geared towards supporting interoperable and scalable production pipelines, abstracting away from the internal data structures of some of the language-specific workflow systems.
Originally designed for computational biology and with many available tool components, Galaxy [Afgan 2018] supports multiple domains. Workflows can be built by manually experimenting with data manipulations in a ‘data playground’ and subsequently converting histories of those to workflows, or by a more traditional drag-and-drop composition approach. New components can be created by wrapping existing programs, with in-built dependency management and automated conversion to executable containers. As such, Galaxy and CWL offer possibilities for a rich canonical workflow component landscape with a workflow management regime that can be both easily FAIR compliant and efficient internally [Wittenburg 2022b]. The WorkflowHub, which facilitates CWL and enables workflows to be registered, shared and published, is mutually coupled with Galaxy so that workflows can be discovered in the Hub and immediately executed in a public-use Galaxy instance.
In the context of the SDR, users can construct institution or project-specific variants of digitization workflows to suit their specific needs. As collections are heterogeneous, different specimen types or specific sets of specimens are likely to have variations and idiosyncrasies in the digitization and processing needed. Tools for automated identification of specimens are likely to be taxon-specific, and as such it seems likely that taxon-specific workflows will become common. In addition, institutions have specific data exchange requirements for their individual collection management systems. Ensuring that workflows can be easily modified in a common environment bridges the gap between community contribution to shared tooling and the bespoke needs of specific institutions/collections.
Although computational workflows typically emphasise scalable automated processing, in practice many also combine automation with manual steps. This feature is also supported by Galaxy and CWL, allowing (for example) manual geocoding and verification during the digitization process of the locations where specimens were collected.
FAIR Digital Objects
Galaxy/CWL environments offer the possibility to integrate generic digital object methods [Hui 2012, Kallinikos 2013, Kahn 2006] for the interactions between workflow components, thus making them able to meet the need and ease the burden of compiling FAIR compliant data throughout the research lifecycle [Wittenburg 2022b].
A digital object exhibiting FAIR characteristics is a FAIR Digital Object [De Smedt 2020] and is defined formally as “a unit composed of data and/or metadata regulated by structures or schemas, and with an assigned globally unique and persistent identifier (PID), which is findable, accessible, interoperable and reusable both by humans and computers for the reliable interpretation and processing of the data represented by the object”.
Supporting ‘FAIRness’ internally and acting as glue between the steps of canonical workflows, FDOs record and can represent the state of a workflow, its inputs and outputs, and the component steps performed in a comprehensive manner [Wittenburg 2022b]. Each FDO is anchored by a globally unique and resolvable, persistent identifier (PID) (such as a DOI®, for example) that clearly refers to one digital entity. The PID resolution offers persistent references to find, access and reuse all information entities that are relevant to access and interpret the content of an FDO. In doing so, the FDO creates a new kind of machine-actionable, meaningful and technology independent unit of information. This is both immediately available and amenable for further use, as well as being comparable to the role of the classical archival storage box when necessary.
Computable Digital Specimens as a kind of FAIR Digital Object
Digital Specimens (DS) are a specific class of FDO that group, manage and allow processing of fragments of information relating to physical natural history specimens. On a one-to-one correspondence a DS authoritatively collates data about a physical specimen (i.e., information extracted and captured from labels by digitization workflows) with other data – often to be found from third-party sources – derived from analysis and use of the specimen.
openDS [openDS 2021] is the developing specification for open Digital Specimens and other related object types, defining:
-
The logical structure and content of Digital Specimen (DS), Basic Image Object (BIO) and other object types, and the operations permitted on them.
-
The handling rules and behaviors governing digital specimen object operations in general.
-
Serialization and packaging as JavaScript Object Notation (JSON) for lightweight data interchange between systems, sub-systems and components of systems (for which, read ‘workflow components’ [Bray 2017].
openDS is essential to future FAIR digitization of natural history collections and to Digital Specimens as self-standing digital objects on the Internet, amenable to computer processing. It contributes to the new transformative generation of FAIR infrastructure and applications based on Digital Object Architecture that is planned for the Distributed System of Scientific Collections (DiSSCo) [Lannom 2020, Addink 2019, Hardisty 2020] European research infrastructure.
Henceforth we refer to these as openDS FDOs.
FAIR packaging of research/workflow objects with RO-Crate
The useful outcomes of research are not just traditional publications nor data products but everything that goes into and supports an investigative work or production pipelining activity. This includes input and intermediate data, parameter settings, final outputs, software programs and workflows, and configuration information sufficient to make the work reproducible. Research objects [Bechhofer 2013] are a general approach to describing and associating all of this content together in a machine-readable form so that it can be easily preserved, shared and exchanged. Workflow objects are a specific subclass of research objects.
RO-Crate1 [Ó Carragáin 2019a, Soiland-Reyes 2022a] has been established as a community standard to practically achieve FAIR packaging of research objects with their structured metadata. Based on well-established Web standards, RO-Crate uses JSON-LD [Sporny 2020] with [schema.org] for its common metadata representation. It is extensible with domain-specific vocabularies in a growing range of specializing RO-Crate profiles, e.g., for domains such as earth sciences [Corcho 2021], biosciences [Goble 2021]; for object types such as data or workflow [Bacall 2022]; or for workflow runs). RO-Crate has been proposed for the implementation of FAIR Digital Objects on the World Wide Web as a common representation of the FDO Metadata objects foreseen by the FDO Framework [Goble 2021, Bonino 2019]. Combined with FAIR Signposting [Van de Sompel 2022] for resolving persistent identifiers (PID) to FDOs on the World Wide Web, these RO-Crates are findable, accessible, interoperable, and reusable by machines to both create and obtain the information they need to function.
Henceforth, we refer to RO-Crate FDOs.
Problem Description
Automating digitization and capturing the process
In the lengthy history of collectors and museums curating artefacts and specimens, we see that there have been and always will be ambiguities, uncertainties, and inaccuracies in interpretations of recorded information and attached labels [Lohonya 2020]. The practices of different collectors and curators vary and change over time. There are constraints of the label medium itself arising from the specifics of accepted preparation and preservation processes (e.g., tiny, handwritten labels pinned to butterflies).
Although systematic digitization of label and other recorded data can help to unify otherwise diverse information (e.g., species names, locations) the digital process and the resulting digital specimen data carry their own assumptions, simplifications, inconsistencies, and limitations. Over time, tools and methods, workflows and data models all evolve and improve. In particular, increasing automation for throughput and accuracy often involves increased assistance from computers and software.
Just as manual curation and improvement work implies the need for good record keeping, so too does working digitally imply the importance of ensuring that sufficient records are captured about the computer-assisted digitization and curation processes (provenance). These justify the produced digital specimen data and propagate credit for work done to their analogue equivalents, and also allow retrospective review, revision or recomputation of the produced data as future needs, practices or knowledge change.
Globally, there is underinvestment and missing technical expertise for wide-scale automated mass digitization. Sharing proven digitization workflows via a repository or registry linked to an individual published journal article presents significant barriers to re-use. Exploiting hosted community environments – in this case Galaxy and WorkflowHub – for the deployed tooling lowers barriers and provides rapid and easy access for institutions with limited capabilities and capacities for digitization. Hosted workflows represent “primacy of method” for a community evolving towards a new research culture that is becoming increasingly dependent on working digitally and collaboratively [De Roure 2010, Hardisty 2016].
Users, user stories and specimen categories
Initially, two kinds of users must be supported: digitizer technicians and collections managers/curators. Five high-level user stories describe and broadly encompass the functionality these users need:
-
As a digitizer, I want to construct a workflow from a set of predefined components, so I can use that workflow to digitize specimens to a predefined specification.
-
As a digitizer, I want to run one or many specimen images through a workflow so I can create new digital specimens.
-
As a collection manager/curator, I want to run one or many digital specimens through a workflow to enrich my digital specimens with further data.
-
As a collection manager/curator, I want to view the metadata of a digitization workflow run so I can understand what happened on that run.
-
As a digitizer, I want to export the output of a digitization run, so I can consume the output of a digitization run into my institution’s collection management system.
To prove the SDR concept, three categories of preserved specimen types have been selected to be supported initially: herbarium sheets, microscope slides and pinned insects (see Figure 1).
The FDO and CWFR approach in the Specimen Data Refinery
Workflows will be designed to support the user categories and stories given above. The performance of the SDR will be evaluated against these specimen types, eventually using several thousand different specimen and label images. This is in anticipation of SDR becoming part of the pivotal technology to achieve high rates of mass FAIR digitization expected through the planned DiSSCo research infrastructure [Lannom 2020, Addink 2019, Hardisty 2020].
FDO types
In the Specimen Data Refinery (see Figure 2) the role of openDS FDOs is planned as the basis for the primary workflow inputs and outputs, and for data transfer and interactions between components within SDR workflows. A single openDS FDO submitted to the beginning of the workflow (or a de novo digitization that is immediately wrapped as a new openDS FDO) becomes modified by each workflow component to produce an incrementally refined openDS FDO. FDOs are acting as the unit of data communication between canonical workflow components, in that each step is immediately creating an FDO with associated FAIR compliant documentation.
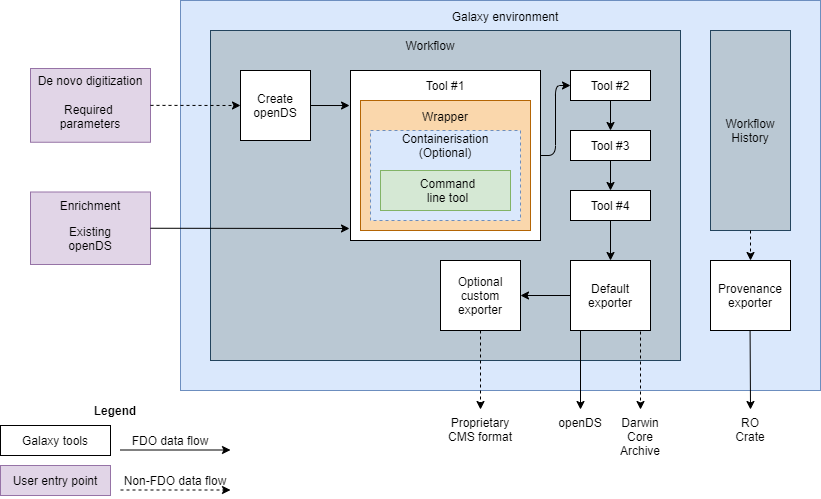
CWFR approach
Adopted for the SDR as a Galaxy workflow management system implementation with ‘de novo digitization’ and ’enrichment’ entry points.
RO-Crate FDOs capture two aspects of a workflow:
-
A Workflow-RO-Crate contains the workflow definition, the computational tools and configuration, graphical image of the workflow, etc; this is the method registered in the WorkflowHub and activated in the Specimen Data Refinery for execution.
-
A Workflow-Run-RO-Crate references (a) and records the details of a specific computational workflow run and its runtime information, with relations to the used and generated FDOs. This captures the digitization provenance that is generated as the openDS FDO makes its journey through a workflow.
The final step in SDR workflows can be a data exporter tool, allowing users to export the entire openDS object as is, or to convert and export it in another format, such as CSV, DarwinCore Archive, etc. This reconfigurable nature of data export allows users to define their own transformer function to allow export to match formats specific to specific collection management systems in use by their institution, such that refined data can be repatriated. The provenance exporter transforms Galaxy workflow history data into a Workflow-Run-RO-Crate FDO.
All FDO types are serialised as JSON.
Canonical components
Each workflow component from a canonical library (to be built, illustrated as tools #1 - #4 in Figure 2 describes what attributes it requires from the openDS FDO to be able to function, and the attributes it will in turn populate or enrich. The interface between the component and the openDS FDO is formed by the wrapper (orange in figure 2) around the (optionally) containerised command-line tool (blue/green in figure 2). Canonical components can be used individually, or in series. The openDS FDO data flows between components will always be of the same type, being modified as the workflow proceeds.
This allows tools to function both as standalone components and as part of any sequence of chained tools, provided that the specific openDS FDO attributes required for a tool to work are pre-populated. This keeps the SDR flexible and customisable for different digitization pipelines.
Two entry points are provided for users of the SDR. One is named as the ‘de novo digitization’ entry point (figure 2) fulfilling the needs of user story (2) where specimens are being newly digitized for the first time. The second entry point, named as the ’enrichment’ entry point (figure 2) fulfils the needs of user story (3) where an existing openDS FDO (or reference to it) can be provided to the SDR as part of the input data.
In parallel to manipulating openDS FDOs, the Refinery gathers the minimum inputs and workflow components required to produce deterministic output and produces a Workflow-Run-RO-Crate FDO.
Experiments and analysis
Experimental workflows
The workflows of the SDR compose different functional components according to specific need: image segmentation, barcode reading, optical character recognition, text contextualisation/entity recognition, geocoding, taxonomic linkage, people linkage, specimen condition checking, automated identification, and data export/conversion. Broadly speaking there are two main kinds of workflow: (i) specimen workflows, where the specimen itself is analysed for morphological traits, colour analysis, condition checking and automated identification; and (ii) text and label workflows, where handwritten, typed or printed text from the image is read, named entities are classified, then linked to identifiers or enhanced through post processing.
Both kinds of workflow can begin with initial openDS object creation based on the submission of specimen image files and accompanying input parameters through a forms-based user interface (de novo digitization entry point); or, alternatively, a pre-existing openDS object with accompanying image object(s)can be supplied as the input (enrichment entry point). Both kinds of workflow also rely on the image segmentation component as the precursor for subsequent workflow steps. Similarly, and if needed both kinds might use a format conversion and export component as their final step; for example, if an openDS FDO is not a natively compatible output for the next consuming application.
Although not within the scope of the present proof-of-concept, other more precise workflows for enhancing specific aspects of existing records can be foreseen. There are many specimen records, for example where locality text, although digitally available, is not yet geocoded. There are records with unlinked or ambiguous collector names that could be linked/disambiguated; and records where unknown specimens still need identifying.
Experimental data and evaluation
Evaluation images datasets
The Refinery will be evaluated using sets of images, each composed of at least 1,000 unique specimens for each of the three categories of preserved specimen types: herbarium sheets, microscope slides and pinned insects. For herbarium sheet images we will reuse an existing benchmark dataset of 1,800 herbarium specimen images with corresponding transcribed data [Dillen 2019b]. For microscope slide and pinned insect specimen images similar evaluation datasets will be prepared against the same label characteristics: written in different languages; printed or handwritten; covering a wide range of dates; both type specimens and general collections and will provide specimens from different families and different parts of the world. Each test dataset set will be composed of images from different institutions to ensure representation of heterogeneity. For the present proof of concept, we limit the scope to Latin alphabet languages. These datasets will also be used to train Refinery models for use in tools (e.g., segmentation, named entity recognition, object/feature detection). All the datasets will be made publicly available with documentation.
Component functional tests
Galaxy has a built-in functional test framework. Tools intended to become components of an SDR canonical library (actually, a Galaxy ToolShed repository) will need to pass previously defined tests within this framework. These tests, based on pre-supplied openDS FDO input and output files containing the properties expected to be populated by the tool, include validating a tool’s own openDS FDO outputs by comparison against the expected output file. It will be necessary to register openDS FDOs as Galaxy custom data types.
Results
openDS FDOs are the core data object at the heart of the SDR, playing not only the workflow input/output role but acting also as a common data structure between tool steps within the workflow. Users can launch the workflow with either an openDS object, for further augmentation by the SDR, or they can complete a form with the specimen information, which is then converted to an openDS object before the workflow proper begins.
Each SDR Galaxy tool defines the properties it requires in JSONPath syntax [JSONPath 2023]. The wrapper validates that these properties exist in the openDS object, plucks them from the openDS JSON, makes them available as named parameters, and passes these through to the tool processing (via either a Docker or Python command line). The wrapper validates the input openDS against the openDS schema, the tool performs its processing and updates the openDS, and the wrapper validates the changed openDS against the schema before writing to disk. For the prototypical SDR, a static, local version of the openDS schema is used. Future iterations will use referenceable versions of the openDS schema, allowing for schema changes and for tools to validate their data input and outputs against versions of the schema.
On ingestion, every openDS is assigned a persistent identifier, ensuring unambiguity and referential integrity for every processed object.
In production, DOIs will be minted by the DiSSCo service; for the proof-of-concept Handles with prefix 20.5000.1025/ will be used.
Discussion
What is being achieved?
The design of the Specimen Data Refinery uses two kinds of FAIR Digital Object – openDS FDOs and RO-Crate FDOs. Each plays a role to ensure ‘FAIRer’ automated digitization for natural history specimens and associated provenance capture:
-
openDS FDOs act both as the input/output interface of a workflow and as the common intermediary pattern (canonical state) between steps within a workflow. They comply with DiSSCo data management principles and needs as outlined in the DiSSCo Data Management Plan [Hardisty 2019b] allowing specimen data to be processed and extended in a fully FAIR manner [Lannom 2020].
-
RO-Crate FDOs record both the workflow definition and information about its configuration (shared as a method object) together with the details and context of the work done during a workflow run; details that are captured proprietarily within the adopted Galaxy environment and transformed to a common pattern (as another kind of canonical state) of provenance for later scrutiny and reproducibility of the work. These kinds of Research Objects [Bechhofer 2013] are an established mechanism whereby computational methods become first-class citizens alongside data, to be easily shared, discussed, reused and repurposed [De Roure 2010].
Both kinds of FDO are essential. They complement one another to support implementation of the FAIR principles, especially the interoperable and reusable principles by making workflows self-documenting. This renders automated whole processes (or fragments thereof) for digitizing and extending natural history specimens’ data as FAIR without adding additional load to the researchers that stand to benefit most from that [Wittenburg 2022b]. Each FDO type originates from different Research Infrastructures (ELIXIR, DiSSCo) with different implementation frameworks. Yet, they interoperate effectively due to their clear roles, common conceptual model and separation of concerns.
Different FDO implementations working together
openDS FDOs have their heritage in distributed digital object services [Kahn 2006] and are implemented through Digital Object Architecture (DOA) [DONA 2021] with Digital Object Interface Protocol (DOIP) [DONA 2018], Digital Object Identifier Resolution Protocol (DO-IRP) [Sun 2003b], and recommendations of the Research Data Alliance [Islam 2020]. Serialised as JSON, they are machine-actionable and compatible with established protocols of the World Wide Web.
RO-Crates are native to the World Wide Web, based on established web protocols, machine-readable metadata using Linked Data Platform methods [Speicher 2015], JSON-LD and Schema.org [Bechhofer 2013, Soiland-Reyes 2022a], and community-accepted packaging mechanisms such as BagIt. This makes RO-Crates straightforward to incorporate into pre-existing platforms such as Galaxy and data repositories such as Zenodo and DataVerse.
Both kinds of FDO use Persistent identifiers (PID), allowing instances to be both uniquely identified and their location to be determined; RO-Crates, as web natives, use URIs whereas openDS, as DOA objects, use Handle PIDs. Instances of both kinds are described by metadata and contain or reference data.
RO-Crates are self-describing using a metadata file and use openly-extensible profiles to type the Crates (profile-typing) to set out expectations for their metadata and content. openDS uses an object-oriented object typing and instance approach to define the structure and content of data/metadata. Complex object types are constructed from basic types, an extension-section basic type. Both approaches seek to avoid locking objects into repository silos, ensuring that FDO instances can be interpreted outside of the contexts in which they were originally created/stored.
Structurally and semantically openDS FDOs and RO-Crate FDOs are potentially isomorphic, although at different granularity levels. Their main difference is in method calling. As a DOA object, openDS would expect to respond to type-specific method calls if these were implemented. RO-Crates delegate actionability to applications that interpret their self-describing profile.
Within the SDR the two kinds of FDO fulfill distinct and interlocking roles for data (openDS) and self-documented method (RO-Crate) so their different forms is not an issue. In future there may be a need to map and convert between the approaches (e.g., for reconstructing past processing), which would be assisted by the common FDO conceptual model [Bonino 2019].
Key domain challenges ahead
For a digitized specimen to conform to FAIR principles, its data must be linked to a vocabulary of terms, but choosing a single vocabulary is likely to cause interoperability issues when cross-linking to resources using another vocabulary, for example Darwin Core, Schema.org, or Access to Biological Collection Data (ABCD). Whilst concepts can be mapped across vocabularies (for example, using Simple Knowledge Organization System (SKOS) matching), such an effort might rapidly become overly complex and cumbersome, as the challenge of the Unified Medical Language System (UMLS) demonstrates. The challenge remains - how is such a mapping exercise maintained at a ‘just enough’ level?
Different Earth Science domains have different use cases for digital records. A digital record produced for biodiversity research is likely to have different granularity, understanding and focus to one produced for climate science. It remains to be seen if a single FAIR Digital Object definition could be produced to satisfy multiple domains, and if different objects could be produced for different domains, what would they look like; and would this hinder future cross-compatibility?
The openDS FDO type produced by the SDR is a new object format for the natural history domain that is foreseen to become an adopted standard over time. Institutional collection management systems will need to be upgraded before they can consume the FDO outputs from the SDR. Early adopters may need assistance to produce SDR exporters matching proprietary ingestion formats. For an interim period, there may be a need for the SDR to output today’s widely used Darwin Core Archives format in parallel.
As the functional requirements of the SDR are emergent, a minimum viable product has been scoped, but this should be contrasted with the notion of a useful product. An MVP is a prototype; a tool to get a project off the ground with enough features to be usable by early adopters, and to build on to learn user requirements. But it is not intended to meet the day-to-day requirements of all users. To nurture future development, care must be taken to continue involving key stakeholders in eliciting further requirements to make the SDR useful for the widest range of users, and from there, develop a rich, configurable tool to allow simple uptake and provide utility for resource-poor collections.
Conclusion and Future Work
The Specimen Data Refinery is likely to garner widespread interest across the Natural History community. Whilst the promise of a scalable, community-driven digitization platform is tantalising for many natural history professionals, the Specimen Data Refinery project is still in its early stages, and, as discussed above key challenges lie ahead.
Although natural history collections are generally catalogued by the taxonomic identity of the curated object, there remains a large historical backlog of unidentified specimens. The Meise Botanic Garden (BE), for example, has an estimated 4 million specimens with at least 11% not yet identified to species level. Furthermore, it is calculated that half of the World’s estimated 70,000 plant species yet to be described have already been collected and are waiting in collections still to be ‘discovered’ [Crusoe 2022]. The same is likely to be true for other groups of organisms, especially insects. Unnamed specimens tend to have lowest priority for digitization and their data are rarely shared. Machine learning as canonical steps in SDR workflows presents a tremendous opportunity to put an identification on these specimens and potentially, to triage them for further taxonomic investigation.
Author Contributions
- Alex Hardisty
- Conceptualization, Investigation, Supervision, Validation, Writing – original draft, Writing – review & editing, Approval.
- Paul Brack
- Investigation, Writing – original draft, Writing – review & editing.
- Carole Goble
- Conceptualization, Supervision, Writing – review & editing
- Laurence Livermore
- Conceptualization, Funding acquisition, Investigation, Writing – original draft, Writing – review & editing.
- Ben Scott
- Investigation, Writing – original draft, Writing – review & editing.
- Quentin Groom
- Funding acquisition, Investigation, Writing – original draft, Writing – review & editing.
- Stuart Owen
- Investigation, Writing – original draft, Writing – review & editing.
- Stian Soiland-Reyes
- Investigation, Writing – original draft, Writing – review & editing.
Contribution types are drawn from CRediT - Contributor Roles Taxonomy.
Acknowledgements
This work has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement numbers 823827 (SYNTHESYS Plus), 871043 (DiSSCo Prepare), 823830 (BioExcel-2), 824087 (EOSC-Life).
References
[Addink 2019] Wouter Addink, Dimitrios Koureas, Ana Rubio (2019):
DiSSCo as a New Regional Model for Scientific Collections in Europe.
Biodiversity Information Science and Standards 3:e37502.
https://doi.org/10.3897/biss.3.37502
[Afgan 2018] Enis Afgan, Dannon Baker, Bérénice Batut, Marius van den Beek, Dave Bouvier, Martin Čech, John Chilton, Dave Clements, Nate Coraor, Björn A Grüning, Aysam Guerler, Jennifer Hillman-Jackson, Saskia Hiltemann, Vahid Jalili, Helena Rasche, Nicola Soranzo, Jeremy Goecks, James Taylor, Anton Nekrutenko, Daniel Blankenberg (2018):\
The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2018 update.
Nucleic Acids Research 46(W1) W537–W544
https://doi.org/10.1093/nar/gky379
[Allan 2019] E Louise Allan, Laurence Livermore, Benjamin Price, Olha Shchedrina,
Vincent Smith (2019):
A Novel Automated Mass Digitisation Workflow for Natural History Microscope Slides.
Biodiversity Data Journal 7:e32342.
https://doi.org/10.3897/BDJ.7.e32342
[Amstutz 2022] Peter Amstutz, Maxim Mikheev, Michael R. Crusoe, Nebojša Tijanić, Samuel Lampa, et al. (2022):
Existing Workflow systems.
Common Workflow Language wiki, GitHub.
https://s.apache.org/existing-workflow-systems updated 2022-09-13,
accessed 2023-01-23.
[Atkinson 2017] Malcolm Atkinson, Sandra Gesing, Johan Montagnat, Ian Taylor (2017):
Scientific workflows: Past, present and future.
Future Generation Computer Systems 75
https://doi.org/10.1016/j.future.2017.05.041
[Bacall 2022] Finn Bacall, Alan R. Williams, Stuart Owen, Stian Soiland-Reyes (2022):
Workflow RO-Crate Profile 1.0.
WorkflowHub community
https://w3id.org/workflowhub/workflow-ro-crate/1.0
[Bechhofer 2013] Sean Bechhofer, Iain Buchan, David De Roure, Paolo Missier, John Ainsworth, Jiten Bhagat, Phillip Couch, Don Cruickshank, Mark Delderfield, Ian Dunlop, Matthew Gamble, Danius Michaelides, Stuart Owen, David Newman, Shoaib Sufi, Carole Goble (2013):
Why Linked Data is not enough for scientists.
Future Generation Computer Systems 29(2) pp. 599–611.
https://doi.org/10.1016/j.future.2011.08.004
[Bonino 2019] Luiz Bonino, Peter Wittenburg, Bonnie Carroll, Alex Hardisty, Mark
Leggott, Carlo Zwölf (2019):
FAIR digital object framework v1.02.
FDOF technical implementation guideline.
Group of European Data Experts in RDA (GEDE-RDA)
https://github.com/GEDE-RDA-Europe/GEDE/blob/master/FAIR%20Digital%20Objects/FDOF/FAIR%20Digital%20Object%20Framework-v1-02.docx
[Bray 2017] Tim Bray (2017):
The JavaScript Object Notation (JSON) Data Interchange Format.
STD 90, RFC 8259
RFC Editor, Internet Engineering Task Force.
https://doi.org/10.17487/rfc8259
[Carranza-Rojas 2017] Jose Carranza-Rojas, Herve Goeau, Pierre Bonnet, Erick Mata-Montero,
Alexis Joly (2017):
Going deeper in the automated identification of Herbarium specimens.
BMC Evolutionary Biology 17(1)
https://doi.org/10.1186/s12862-017-1014-z
[Corcho 2021] Oscar Corcho, Esteban González, Daniel Garijo, Raul Palma (2021):
D5.1 RO Model Adapted to EOSC
RELIANCE deliverable, Zenodo
https://doi.org/10.5281/zenodo.4913285
[Crusoe 2022] Michael R. Crusoe, Sanne Abeln, Alexandru Iosup, Peter Amstutz, John
Chilton, Nebojša Tijanić, Hervé Ménager, Stian Soiland-Reyes, Bogdan
Gavrilović, Carole Goble, The CWL Community (2022):
Methods Included: Standardizing Computational Reuse and Portability with the Common Workflow Language.
Communications of the ACM 65(6)
https://doi.org/10.1145/3486897
[De Roure 2010] David De Roure, Carole Goble (2010):
Anchors in shifting sand: the primacy of method in the web of data.
Proceedings of the WebSci10: Extending the Frontiers of Society
On-Line, at Web Science Conference 2010 Raleigh, NC: US
2010-04-26/–27
https://web.archive.org/web/20140828142306/http://journal.webscience.org/325/
http://eprints.soton.ac.uk/id/eprint/270817
[De Smedt 2020] Koenraad De Smedt, Dimitris Koureas, Peter Wittenburg (2020):
FAIR Digital Objects for Science: From Data Pieces to Actionable Knowledge Units.
Publications 8(2):21
https://doi.org/10.3390/publications8020021
[Dillen 2019b] Mathias Dillen, Quentin Groom, Simon Chagnoux, Anton Güntsch, Alex
Hardisty, Elspeth Haston, Laurence Livermore, Veljo Runnel, Leif
Schulman, Luc Willemse, Zhengzhe Wu, Sarah Phillips (2019):
A benchmark dataset of herbarium specimen imagfes with label data.
Biodiversity Data Journal 7:e31817.
https://doi.org/10.3897/BDJ.7.e31817
[DONA 2018] DONA Foundation (2018):
Digital Object Interface Protocol specification, version 2.0.
DONA Foundation
https://hdl.handle.net/0.DOIP/DOIPV2.0
[DONA 2021] DONA Foundation (2021):
Digital Object Architecture.
https://www.dona.net/node/88 (accessed 2021-08-10)
[Ferrier 2019] Mark Hereld, Nicola Ferrier (2019):
LightningBug ONE: An experiment in high-throughput digitization of pinned insects.
Biodiversity Information Science and Standards 3:e37228.
https://doi.org/10.3897/biss.3.37228
[GBIF 2021] GBIF Secretariat. (2021):
GBIF Science Review 2020.
https://doi.org/10.35035/bezp-jj23
[Goble 2021] Carole Goble, Stian Soiland-Reyes, Finn Bacall, Stuart Owen, Alan
Williams, Ignacio Eguinoa, Bert Droesbeke, Simone Leo, Luca Pireddu,
Laura Rodríguez-Navas, José Mª Fernández, Salvador Capella-Gutierrez,
Hervé Ménager, Björn Grüning, Beatriz Serrano-Solano, Philip Ewels,
Frederik Coppens (2021):
Implementing FAIR Digital Objects in the EOSC-Life Workflow Collaboratory.
Zenodo
https://doi.org/10.5281/zenodo.4605654
[Goble 2021] Carole Goble, Stian Soiland-Reyes, Finn Bacall, Stuart Owen, Alan Williams, Ignacio Eguinoa, Bert Droesbeke, Simone Leo, Luca Pireddu, Laura Rodríguez-Navas, José Mª Fernández, Salvador Capella-Gutierrez, Hervé Ménager, Björn Grüning, Beatriz Serrano-Solano, Philip Ewels, Frederik Coppens (2021):
Implementing FAIR Digital Objects in the EOSC-Life Workflow Collaboratory.
Zenodo
https://doi.org/10.5281/zenodo.4605654
[Gössner 2023] JSONPath WG (2023):
JSONPath: Query Expressions for JSON.
Stefan Gössner, Glyn Normington, Carsten Bormann (eds).
Internet-Draft draft-ietf-jsonpath-base-10
https://datatracker.ietf.org/doc/id/draft-ietf-jsonpath-base-10
[Groom 2020] Quentin Groom, Anton Güntsch, Pieter Huybrechts, Nicole Kearney, Siobhan Leachman, Nicky Nicolson, Roderic D M Page, David P Shorthouse, Anne E Thessen, Elspeth Haston (2020):
People are essential to linking biodiversity data.
Database 2020
https://doi.org/10.1093/database/baaa072
[Hardisty 2016] Alex R. Hardisty, Finn Bacall, Niall Beard, Maria-Paula Balcázar-Vargas, Bachir Balech, Zoltán Barcza, Sarah J. Bourlat, Renato De Giovanni, Yde de Jong, Francesca De Leo, Laura Dobor, Giacinto Donvito, Donal Fellows, Antonio Fernandez Guerra, Nuno Ferreira, Yuliya Fetyukova, Bruno Fosso, Jonathan Giddy, Carole Goble, Anton Güntsch, Robert Haines, Vera Hernández Ernst, Hannes Hettling, Dóra Hidy, Ferenc Horváth, Dóra Ittzés, Péter Ittzés, Andrew Jones, Renzo Kottmann, Robert Kulawik, Sonja Leidenberger, Päivi Lyytikäinen-Saarenmaa, Cherian Mathew, Norman Morrison, Aleksandra Nenadic, Abraham Nieva de la Hidalga, Matthias Obst, Gerard Oostermeijer, Elisabeth Paymal, Graziano Pesole, Salvatore Pinto, Axel Poigné, Francisco Quevedo Fernandez, Monica Santamaria, Hannu Saarenmaa, Gergely Sipos, Karl-Heinz Sylla, Marko Tähtinen, Saverio Vicario, Rutger Aldo Vos, Alan R. Williams, Pelin Yilmaz (2016):
BioVeL: a virtual laboratory for data analysis and modelling in biodiversity science and ecology.
BMC Ecology 16(1)
https://doi.org/10.1186/s12898-016-0103-y
[Hardisty 2019b] Alex Hardisty (2019):
Provisional Data Management Plan for DiSSCo infrastructure.
Zenodo, DiSSCo Deliverable D6.6
https://doi.org/10.5281/zenodo.3532937
[Hardisty 2020] Alex Hardisty, Hannu Saarenmaa, Ana Casino, Mathias Dillen, Karsten Gödderz, Quentin Groom, Helen Hardy, Dimitris Koureas, Abraham Nieva de la Hidalga, Deborah Paul, Veljo Runnel, Xavier Vermeersch, Myriam van Walsum, Luc Willemse (2020):
Conceptual design blueprint for the DiSSCo digitization infrastructure - DELIVERABLE D8.1.
Research Ideas and Outcomes 6:e54280.
https://doi.org/10.3897/rio.6.e54280
[Harrow 2021] Jennifer Harrow, John Hancock, ELIXIR-EXCELERATE Community, Niklas
Blomberg (2021):
ELIXIR-EXCELERATE: establishing Europe’s data infrastructure for the life science research of the future.
EMBO Journal 40(6):e107409
https://doi.org/10.15252/embj.2020107409
[Heberling 2019] J Mason Heberling, L Alan Prather, Stephen J Tonsor (2019):
The Changing Uses of Herbarium Data in an Era of Global Change: An Overview Using Automated Content Analysis.
BioScience 69(10)
https://doi.org/10.1093/biosci/biz094
[Heberling 2021] J Mason Heberling, Joseph T Miller, Daniel Noesgaard, Scott B Weingart, Dmitry Schigel (2021):
Data integration enables global biodiversity synthesis.
Proceedings of the National Academy of Sciences 118(6)
https://doi.org/10.1073/pnas.2018093118
[Hereld 2019] Mark Hereld, Nicola Ferrier (2019):
LightningBug ONE: An experiment in high-throughput digitization of pinned insects.
Biodiversity Information Science and Standards 3:e37228.
https://doi.org/10.3897/biss.3.37228
[Hui 2012] Yuk Hui (2012):
What is a Digital Object?
Metaphilosophy 43(4)
https://doi.org/10.1111/j.1467-9973.2012.01761.x
[Hui 2012] Yuk Hui (2012):
What is a Digital Object?
Metaphilosophy 43(4)
https://doi.org/10.1111/j.1467-9973.2012.01761.x
[Hussein 2021] Burhan Rashid Hussein, Owais Ahmed Malik, Wee-Hong Ong, Johan Willem Frederik Slik (2021):
Application of Computer Vision and Machine Learning for Digitized Herbarium Specimens: A Systematic Literature Review.
arXiv 2104.08732v1
https://doi.org/10.48550/arXiv.2104.08732
[Islam 2020] Sharif Islam, Alex Hardisty, Wouter Addink, Claus Weiland, Falko Glöckler (2020):
Incorporating RDA Outputs in the Design of a European Research Infrastructure for natural history Collections.
Data Science Journal 19:50
https://doi.org/10.5334/dsj-2020-050
[JSONPath 2023] JSONPath WG (2023):
JSONPath: Query Expressions for JSON.
Stefan Gössner, Glyn Normington, Carsten Bormann (eds).
Internet-Draft draft-ietf-jsonpath-base-10
https://datatracker.ietf.org/doc/id/draft-ietf-jsonpath-base-10
[Kahn 2006] Robert Kahn, Robert Wilensky (2006):
A framework for distributed digital object services.
International Journal on Digital Libraries 6
https://doi.org/10.1007/s00799-005-0128-x
[Kallinikos 2013] Jannis Kallinikos, Aleksi Ville Aaltonen, Attila Marton (2013):
The ambivalent ontology of digital artifacts.
MIS Quarterly 37(2) pp. 357–370.
ISSN 0276-7783
https://www.jstor.org/stable/43825913
https://misq.umn.edu/the-ambivalent-ontology-of-digital-artifacts.html
[Kharouba 2019] Heather M. Kharouba, Jayme M. M. Lewthwaite, Rob Guralnick, Jeremy T.
Kerr, Mark Vellend (2019):
Using insect natural history collections to study global change impacts: challenges and opportunities.
Philosophical Transactions of the Royal Society B: Biological Sciences
374(1763):20170405
https://doi.org/10.1098/rstb.2017.0405
[Knyshov 2021] Alexander Knyshov, Samantha Hoang, Christiane Weirauch (2021):
Pretrained Convolutional Neural Networks Perform Well in a Challenging Test Case: Identification of Plant Bugs (Hemiptera: Miridae) Using a Small Number of Training Images.
Insect Systematics and Diversity 5(2)
https://doi.org/10.1093/isd/ixab004
[Lannom 2020] Larry Lannom, Dimitris Koureas, Alex R. Hardisty (2020):
FAIR Data and Services in Biodiversity Science and Geoscience.
Data Intelligence 2(1–2):122–130.
https://doi.org/10.1162/dint_a_00034
[Little 2020] Damon P. Little, Melissa Tulig, Kiat Chuan Tan, Yulong Liu, Serge Belongie, Christine Kaeser‐Chen, Fabián A. Michelangeli, Kiran Panesar, R.V. Guha, Barbara A. Ambrose (2020):
An algorithm competition for automatic species identification from herbarium specimens.
Applications in Plant Sciences 8(6):e11365
https://doi.org/10.1002/aps3.11365
[Lohonya 2020] Krisztina Lohonya, Laurence Livermore, Malcolm Penn (2020):
Georeferencing the Natural History Museum’s Chinese type collection: of plateaus, pagodas and plants.
Biodiversity Data Journal 8:e50503.
https://doi.org/10.3897/BDJ.8.e50503
[Lughadha 2019] Eimear M. Nic Lughadha, Vanessa Graziele Staggemeier, Thais N. C.
Vasconcelos, Barnaby E. Walker, Cátia Canteiro, Eve J. Lucas (2019):
Harnessing the potential of integrated systematics for conservation of taxonomically complex, megadiverse plant groups.
Conservation Biology 33(3)
https://doi.org/10.1111/cobi.13289
[Nelson 2019a] Gil Nelson, Shari Ellis (2019):
The history and impact of digitization and digital data mobilization on biodiversity research.
Philosophical Transactions of the Royal Society B: Biological Sciences
374(1763):20170391
https://doi.org/10.1098/rstb.2017.0391
[Nelson 2019b] Gil Nelson, Deborah L Paul (2019):
DiSSCo, iDigBio and the Future of Global Collaboration.
Biodiversity Information Science and Standards 3:e37896.
https://doi.org/10.3897/biss.3.37896
[Nieva de la Hidalga 2021] Abraham Nieva de la Hidalga, Paul L. Rosin, Xianfang Sun, Laurence
Livermore, James Durrant, James Turner, Mathias Dillen, Alicia Musson,
Sarah Phillips, Quentin Groom, Alex Hardisty (2022):
Cross-validation of a semantic segmentation network for natural history collection specimens.
Machine Vision and Applications 33(3)
https://doi.org/10.1007/s00138-022-01276-z
[Ó Carragáin 2019a] Eoghan Ó Carragáin, Carole Goble, Peter Sefton,
Stian Soiland-Reyes (2019):
A lightweight approach to research object data packaging.
Bioinformatics Open Source Conference (BOSC2019),
2019-07-24/2019-07-25, Basel, Switzerland.
https://doi.org/10.5281/zenodo.3250687
[openDS 2021] openDS (2021):
Draft specification for open Digital Specimens (openDS)
https://github.com/DiSSCo/openDS (accessed 2021-08-10)
[Owen 2020] David Owen, Quentin Groom, Alex Hardisty, Thijs Leegwater, Laurence Livermore, Myriam van Walsum, Noortje Wijkamp, Irena Spasić (2020):
Towards a scientific workflow featuring Natural Language Processing for the digitisation of natural history collections.
Research Ideas and Outcomes 6:e58030.
https://doi.org/10.3897/rio.6.e58030
[Price 2018] Benjamin Wills Price, Steen Dupont, Elizabeth Louise Allan, Vladimir
Blagoderov, Alice Jenny Butcher, James Durrant, Pieter Holtzhausen,
Phaedra Kokkini, Laurence Livermore, Helen Hardy, Vincent Smith (2018):
ALICE: Angled Label Image Capture and Extraction for high throughput insect specimen digitisation.
OSF
https://doi.org/10.31219/osf.io/s2p73
[Pryer 2020] Kathleen M. Pryer, Carlo Tomasi, Xiaohan Wang, Emily K. Meineke, Michael D. Windham (2020):
Using computer vision on herbarium specimen images to discriminate among closely related horsetails (Equisetum).
Applications in Plant Sciences 8(6):e11372
https://doi.org/10.1002/aps3.11372
[Pryer 2022] Kathleen M. Pryer, Carlo Tomasi, Xiaohan Wang, Emily K. Meineke, Michael D. Windham (2020):
Using computer vision on herbarium specimen images to discriminate among closely related horsetails (Equisetum).
Applications in Plant Sciences 8(6):e11372
https://doi.org/10.1002/aps3.11372
[schema.org] Schema.org - Schema.org
https://schema.org/ (accessed 2021-08-10).
[Soiland-Reyes 2022a] Stian Soiland-Reyes, Peter Sefton, Mercè Crosas, Leyla Jael Castro,
Frederik Coppens, José M. Fernández, Daniel Garijo, Björn Grüning, Marco
La Rosa, Simone Leo, Eoghan Ó Carragáin, Marc Portier, Ana Trisovic,
RO-Crate Community, Paul Groth, Carole Goble (2022):
Packaging research artefacts with RO-Crate.
Data Science 5(2)
https://doi.org/10.3233/DS-210053
[Speicher 2015] Steve Speicher, John Arwe, Ashok Malhotra (eds) (2015):
Linked Data Platform 1.0.
W3C Recommendation 26 February 2015
http://www.w3.org/TR/2015/REC-ldp-20150226/
[Sporny 2020] Manu Sporny, Dave Longley, Gregg Kellogg, Markus Lanthaler, Pierre-Antoine Champin, Niklas Lindström (2020):
JSON-LD 1.1: A JSON-based Serialization for Linked Data.
W3C Recommendation 16 July 2020
https://www.w3.org/TR/2020/REC-json-ld11-20200716/
[Sun 2003b] Sam Sun, Sean Reilly, Larry Lannom, Jason Petrone (2003):
Handle System Protocol (ver 2.1) Specification.
RFC Editor, RFC 3652
https://doi.org/10.17487/rfc3652
[Sweeney 2018] Patrick W. Sweeney, Binil Starly, Paul J. Morris, Yiming Xu, Aimee Jones, Sridhar Radhakrishnan, Christopher J. Grassa, Charles C. Davis (2018):
Large-scale digitization of herbarium specimens: Development and usage of an automated, high-throughput conveyor system.
Taxon 67(1)
https://doi.org/10.12705/671.10
[Tegelberg 2017] Riitta Tegelberg, Jere Kahanpaa, Janne Karppinen, Tero Mononen, Zhenzhe
Wu, Hannu Saarenmaa (2017):
Mass Digitization of Individual Pinned Insects Using Conveyor-Driven Imaging.
2017 IEEE 13th International Conference on E-Science (e-Science)
https://doi.org/10.1109/eScience.2017.85
[Thiers 2016] Barbara M. Thiers, Melissa C. Tulig, Kimberly A. Watson (2016):
Digitization of the New York Botanical Garden herbarium.
Brittonia, 68(3)
https://doi.org/10.1007/s12228-016-9423-7
[Triki 2020] Abdelaziz Triki, Bassem Bouaziz, Walid Mahdi, Jitendra Gaikwad (2020):
Objects Detection from Digitized Herbarium Specimen based on Improved YOLO V3.
Proceedings of the 15th International Joint Conference on Computer
Vision, Imaging and Computer Graphics Theory and Applications 4
https://doi.org/10.5220/0009170005230529
[Unger 2016] Jakob Unger, Dorit Merhof, Susanne Renner (2016):
Computer vision applied to herbarium specimens of German trees: testing the future utility of the millions of herbarium specimen images for automated identification.
BMC Evolutionary Biology 16(1)
https://doi.org/10.1186/s12862-016-0827-5
[Van de Sompel 2022] Herbert Van de Sompel, Martin Klein, Shawn Jones, Michael L. Nelson, Simeon Warner, Anusuriya Devaraju, Robert Huber, Wilko Steinhoff, Vyacheslav Tykhonov, Luc Boruta, Enno Meijers, Stian Soiland-Reyes, Mark Wilkinson (2022):
FAIR Signposting Profile. (version 20220727).
https://signposting.org/FAIR/
[Walton 2020a] Stephanie Walton, Laurence Livermore, Olaf Bánki, Robert Cubey, Robyn Drinkwater, Markus Englund, Carole Goble, Quentin Groom, Christopher Kermorvant, Isabel Rey, Celia Santos, Ben Scott, Alan Williams, Zhengzhe Wu (2020):
Landscape Analysis for the Specimen Data Refinery.
Research Ideas and Outcomes 6:e57602
https://doi.org/10.3897/rio.6.e57602
[Walton 2020b] Stephanie Walton, Laurence Livermore, Mathias Dillen, Sofie De Smedt, Quentin Groom, Anne Koivunen, Sarah Phillips (2020):
A cost analysis of transcription systems.
Research Ideas and Outcomes 6:e56211.
https://doi.org/10.3897/rio.6.e56211
[Watanabe 2019] Myrna E Watanabe (2019):
The Evolution of Natural History Collections: New research tools move specimens, data to center stage.
BioScience 69(3)
https://doi.org/10.1093/biosci/biy163
[Wilkinson 2016] Mark D. Wilkinson, Michel Dumontier, IJsbrand Jan Aalbersberg, Gabrielle Appleton, Myles Axton, Arie Baak, Niklas Blomberg, Jan-Willem Boiten, Luiz Bonino da Silva Santos, Philip E. Bourne, Jildau Bouwman, Anthony J. Brookes, Tim Clark, Mercè Crosas, Ingrid Dillo, Olivier Dumon, Scott Edmunds, Chris T. Evelo, Richard Finkers, Alejandra Gonzalez-Beltran, Alasdair J.G. Gray, Paul Groth, Carole Goble, Jeffrey S. Grethe, Jaap Heringa, Peter A.C ’t Hoen, Rob Hooft, Tobias Kuhn, Ruben Kok, Joost Kok, Scott J. Lusher, Maryann E. Martone, Albert Mons, Abel L. Packer, Bengt Persson, Philippe Rocca-Serra, Marco Roos, Rene van Schaik, Susanna-Assunta Sansone, Erik Schultes, Thierry Sengstag, Ted Slater, George Strawn, Morris A. Swertz, Mark Thompson, Johan van der Lei, Erik van Mulligen, Jan Velterop, Andra Waagmeester, Peter Wittenburg, Katherine Wolstencroft, Jun Zhao, Barend Mons (2016):
The FAIR Guiding Principles for scientific data management and stewardship.
Scientific Data 3(1):160018
https://doi.org/10.1038/sdata.2016.18
[Wittenburg 2022b] Peter Wittenburg, Alex Hardisty, Yann Le Franc, Amirpasha Mozaffari,
Limor Peer, Nikolay A. Skvortsov, Zhiming Zhao, Alessandro
Spinuso (2022):
Canonical Workflows to Make Data FAIR.
Data Intelligence 4(2)
https://doi.org/10.1162/dint_a_00132
-
See Section 5.1 ↩︎