Supplement: Linking provenance and meta-provenance for an AI based experiment using the CPM
Linking provenance and meta-provenance for an AI based experiment using the CPM
Authors: Rudolf Wittner, Matej Gallo, Simone Leo, Cecilia Mascia, Francesca Frexia, Markus Plass, Stian Soiland-Reyes, Heimo Müller, Jörg Geiger, Petr Holub
Research objects, such as biological or environmental samples or data, are commonly exchanged between research groups or organizations. Consequently, each organization can provide provenance information only about a part of the research object’s life cycle. The Common Provenance Model1 (CPM) is an extension of the W3C PROV standard2 for provenance information and a conceptual foundation for the ISO 23494 series. The CPM aims to enable creation of provenance chains – sets of interlinked and possibly distributed provenance bundles spread across various organizations involved in a research object handling. The aim of this document is to present how the mechanism for linking provenance and meta-provenance is integrated with the CPM and implemented for a use case.
The implementation is created for a use case from the digital pathology domain, and is focused on documenting steps of an AI-based experiment execution. A detailed description of the use case and the core concepts of the CPM was presented in our previous work3. In this work, we re-use the original example and extend it with adoption of persistent identifiers (PIDs) for the connectors and resolvable URIs for provenance bundles. In addition, we demonstrate the generation of meta-provenance.
According to the W3C PROV provenance standard, provenance information is represented as a graph with annotated nodes and edges, also called provenance structures. The nodes of the graph represent entities, activities, or agents, and the edges represent their mutual relations. The PROV standard stipulates that each provenance structure is identified with an identifier which is a qualified name consisting of two parts: a namespace denoted by an optional prefix and a local part. Such a qualified name can be mapped into an IRI by concatenating the namespace and the local part. The IRI may be resolvable.
The following table lists prefixes and associated namespaces used in this document and in the implementation.
| Prefix | Namespace | Description |
| doi | http://doi.org/10.58092/ | The prefix is used as part of persistent identifiers generated in the presented example. |
| cpm | CPM_URI_PLACEHOLDER4 | The prefix is used to denote attributes defined in the CPM. |
| resolvable_prefix | http://gitlab.ics.muni.cz/422328/pid-test/-/blob/master/provn/ | The prefix is used for identification of resolvable provenance structures identifiers. |
| mapping | https://gitlab.ics.muni.cz/422328/pid-test/-/tree/master/pid | The prefix is used for identification of mapping between a persistent identifier and a content, to which the identifier resolves to. |
Each time we show a resolvable identifier consisting of a prefix and a local part, we mean an identifier that is formed by replacing the prefix with the corresponding namespace IRI and concatenating it with the local part.
Provenance chain for the AI pipeline
The AI pipeline execution consists of three steps, and each of the steps can be executed individually. For that reason, the corresponding provenance chain documenting an execution of the pipeline is designed as three mutually interconnected provenance components (technically implemented as PROV bundles serialized into standalone files), so that each of the components documents an individual part of the pipeline execution:
-
Image data preprocessing bundle (resolvable_prefix:preproc.provn) documents processing of the input dataset as required for the training and testing of the AI model.
-
AI model training bundle (resolvable_prefix:train.provn) documents how the AI model was trained using the training dataset from the Image data preprocessing step.
-
AI model evaluation bundle (resolvable_prefix:eval.provn) documents how the trained model from the AI model training step was evaluated using the testing dataset from Image data preprocessing step.
The resulting provenance information is implemented by transformation of existing information present in logs, configuration files, or file system into a CPM-based representation which is consecutively exported into four files – a file per each step of the pipeline + an additional file for meta-provenance. The resulting provenance chain and corresponding meta-provenance is schematically depicted in Figure 1.
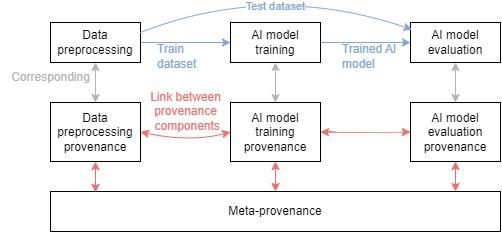
Figure 1: Schema of the generated provenance and meta-provenance for the AI pipeline execution.
Each provenance component contains a set of connectors which represent a snapshot of an exchanged object (dataset or the AI model) in various time instances, and which interconnect individual provenance bundles. The presented mechanism for provenance and meta-provenance linking prescribes that each of the connectors is identified with a persistent identifier, which resolves to:
-
A serialization of the corresponding connector;
-
Identifiers of the bundles, in which the connector is present;
-
Identifiers of the meta-bundles containing meta-provenance of bundles in which the connector is present.
Semantics of each connector follows its general semantics defined in the CPM. Semantics of the connectors applied in this use case are summarized in the following table.
| Connector ID | Semantics of the connector |
| doi:WSIDataExternalInputConnector | The connector represents the input dataset at the time when it was used as an input for the data preprocessing step. |
| doi:datasetTrainConnector | The connector represents the train dataset at the time when it was provided from the data preprocessing to the AI model training step. |
| doi:datasetEvalConnector | The connector represents the test dataset at the time when it was provided from the data preprocessing to the AI model evaluation step. |
| doi:datasetExternalInputConnector | The connector represents the training dataset at the time when it was used by the AI model training step. |
| doi:trainedModelConnector | The connector represents the trained model at the time when it was provided from the AI model training step to the AI model evaluation step. |
| doi:trainedNetExternalInputConnector | The connector represents the trained AI model at the time when it was used for the model evaluation. |
| doi:testDatasetExternalInputConnector | The connector represents the test dataset at the time when it was used for the model evaluation. |
The following table summarizes associations between generated connectors, bundles, and meta-bundles.
| Connector PID | Bundles in which the connector is present | Corresponding meta-bundle | |
| 1. | doi:WSIDataExternalInputConnector | resolvable_prefix:preproc.provn | resolvable_prefix:meta.provn |
| 2. | doi:datasetTrainConnector | resolvable_prefix:preproc.provn, resolvable_prefix:train.provn | resolvable_prefix:meta.provn |
| 3. | doi:datasetEvalConnector | resolvable_prefix:preproc.provn, resolvable_prefix:eval.provn | resolvable_prefix:meta.provn |
| 4. | doi:datasetExternalInputConnector | resolvable_prefix:train.provn | resolvable_prefix:meta.provn |
| 5. | doi:trainedModelConnector | resolvable_prefix:train.provn, resolvable_prefix:eval.provn | resolvable_prefix:meta.provn |
| 6. | doi:trainedNetExternalInputConnector | resolvable_prefix:eval.provn | resolvable_prefix:meta.provn |
| 7. | doi:testDatasetExternalInputConnector | resolvable_prefix:eval.provn | resolvable_prefix:meta.provn |
Provenance generation procedure
The resulting provenance information can be divided into three categories: 1) provenance information; 2) meta-provenance; 3) connector-bundle mapping information to which the connector PIDs resolve to. Additionally, each of these are mutually interconnected by presence of particular resolvable identifiers, which is depicted in Figure 2.
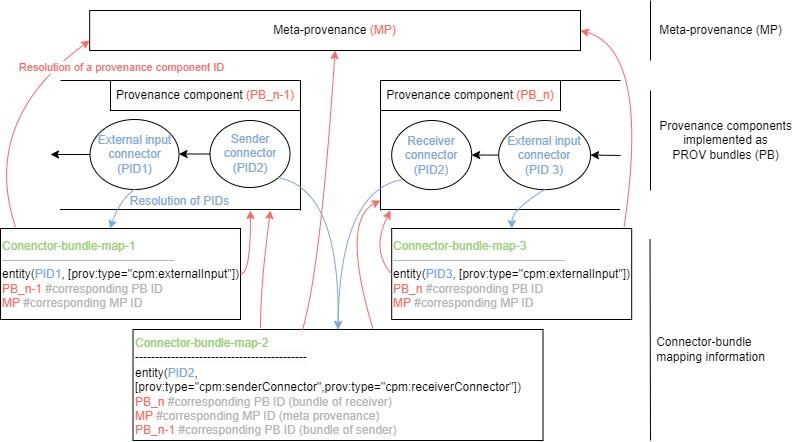
Figure 2:General schema of how the resulting provenance, meta-provenance and connector-bundle mapping information are interlinked using PIDs for the AI experiment. Each provenance bundle (PB) contains a connector PID which resolves to the corresponding connector-bundle mapping.The mapping contains relevant PB and meta provenance (MP) identifiers which resolve to the actual bundle’s content.
The resulting finalized provenance requires generation of corresponding identifiers (resolvable or persistent), generation of the connector-bundle mapping information, and generation of the actual provenance and meta-provenance. The resulting provenance generation procedure consists of the following steps.
- Determination of the bundle identifiers – resolvable URIs. Resolution of the URI returns the content of a particular bundle. The URI must be known before the actual bundle is published on that URI, because the bundle contains the URI5.
resolvable_prefix:preproc.provn
resolvable_prefix:train.provn
resolvable_prefix:eval.provn
resolvable_prefix:meta.provn
- Determination of connector-bundle mapping identifiers – resolvable URIs. Resolution of the URI returns the content to which a connector PID will later resolve to. The number of these identifiers is equal to the number of connectors. The URI must be known before the actual corresponding PID is published (the URI is part of the PID publication).
mapping:WSIDataExternalInputConnector.provn
mapping:datasetEvalReceiverConnector.provn
mapping:datasetEvalSenderConnector.provn
…
- Generation and assignment of PIDs to connector-bundle mapping identifiers. During this step, it is made sure that the PID is available and reserved for the provenance purpose. Consequently, the PID is assigned to an URI, which the PID resolves to, resulting in a list of pairs registered in a PID publisher:
doi:WSIDataExternalInputConnector - mapping:WSIDataExternalInputConnector.provn
doi:datasetTrainConnector - mapping:datasetTrainConnector.provn
doi:datasetEvalConnector - datasetEvalConnector.provn
…
- Generation of provenance information according to the CPM, which includes the generated bundle identifiers and the connector identifiers (PIDs) for connectors:
document
bundle resolvable\_prefix:preproc.provn
entity(doi:WSIDataExternalInputConnector,\[…\])
…
endBundle
endDocument
document
bundle prefix:resolvable\_prefix:meta.provn
…
entity(resolvable\_prefix:preproc.provn)
…
endBundle
endDocument
-
Generation of connector-bundle mapping. For each connector PID, create the content for corresponding connector-bundle mapping, containing serialization of a particular connector including its identifier (PID), identifier of the bundle in which the connector is included and the identifier of corresponding meta-bundle.
-
Publication of the connector-bundle mapping. After this step, the connector-bundle mapping is available after the corresponding connector-bundle mapping identifier resolution.
-
Publication of the finalized provenance information. After this step, the provenance information is available after the corresponding bundle identifier resolution.
-
Publication of the connector’s PIDs. After this step, the connector PID resolution redirects the resolution request to the connector-bundle mapping identifier (URI), and this consequently resolves to the connector-bundle mapping information. As the PIDs were registered earlier, this step should not fail due to unavailability of the selected PID.
The generated connector-bundle mapping identifiers MUST NOT identify specific versions of that information, but should identify the latest version of that information. The reason is that the identifier must stay the same after the content is updated, e.g. when a receiver of a described object generates a new provenance bundle in a provenance chain and reflects this in the connector-bundle mapping information.
If the proposed mechanism would be deployed in a production environment, the described procedure should be implemented as a transaction, i.e. failure of a step will cause the other steps to be rolled back, and depending on the actual reason for failure and order of the steps, appropriate corrective actions should be taken. For instance, if the final step – the publication of the PID – fails for some reason, the generated provenance including the PID is not valid anymore, since the PID is included in the provenance and in the connector bundle mapping, but it does not resolve to the required content.
Representation of the connector-bundle mapping information
The connector PID resolves to corresponding connector-bundle mapping information, which we have represented as a PROV document serialized into PROV-N notation6. To represent the required bundle identifiers in the resulting provenance information, we re-use the original sender and receiver connector attributes:
-
cpm:senderBundleId – the attribute present in the receiver connector;
-
cpm:receiverBundleId - the attribute present in the sender connector.
In addition, we introduce new attributes for external input connectors and meta-bundle:
-
cpm:currentBundle - value of this attribute is an identifier of a bundle, in which the connector is present;
-
cpm:metabundle - value of this attribute is an identifier of a meta-bundle corresponding to the cpm:currentBundle value.
As a result, all provenance information can be exchanged along with an exchanged research object by providing the PID of the corresponding connector from a sender to a receiver. This way, a receiver can use the PID as a starting point to retrieve relevant provenance information (Figure 3). If a connector is present in multiple bundles, the connector may be represented in connector-bundle mapping information as multiple provenance statements.

Figure 3: Illustration of how the connector PID can be used to retrieve a sender’s provenance bundle.
In a case when the attributes referring to bundles are included not only in the PID-resolved content, but are also present in the provenance chain, the links between components of a chain become redundant: one link is implemented directly by the presence of corresponding attribute in the connector, and the second link is implemented through the resolution of the PID. Such a redundancy may provide better integrity of the provenance chain, for instance, in cases when a provenance component moves to another location and the receiver is not notified, but the PID reference is updated (or vice versa). Additionally, if a provenance component ceases to exist (e.g., because the corresponding organization bankrupts or disappears), the redundant link to PID resolved content might provide additional contextual information about the referenced component, which would be otherwise lost.
Providing recommendations for creation of the redundant links and determination of responsibilities for notification of affected parties will be part of the future development of the CPM and the related ISO standard.
Implementation notes
The PIDs used for our implementation are internationally standardized Digital Object Identifiers (DOIs)7. We use the DataCite8 registration agency and the identifiers’ prefix of Masaryk University. As a result, the global uniqueness and persistence of the generated identifiers are guaranteed.
The resulting provenance files and PID-bundle mappings are hosted on a GitLab9 instance at the Institute of Computer Science at Masaryk University. The main reason for selecting GitLab for hosting the files was that it enabled us to determine the URIs of published files before the publication, which is necessary for inclusion of the URIs in these files. The same functionality, which would be also a preferred option, can be achievable by deploying our own web server where we would host the files. In addition, as GitLab is open-source software, it does not cause a vendor lock and provides means to deploy new instances of the SW in cases when the University instance would cease to operate. This way, the content to which the PIDs resolve should be easily migrated, providing better sustainability of the PIDs.
Packing the artifacts into an RO Crate
The computational artifacts used and generated by the AI pipeline are packed together into an RO-Crate that conforms to the CPM RO-Crate10 and Process Run Crate11 profiles specifications. The resulting RO-Crate contains the actual copies or references to: the underlying python scripts of the AI pipeline, input WSI files, intermediate results of the computation, log files, CPM files, and configuration files. As a result, the artifacts are packed together in a sharable interoperable manner. The structure of the resulting RO Crate is depicted in Figure 4.
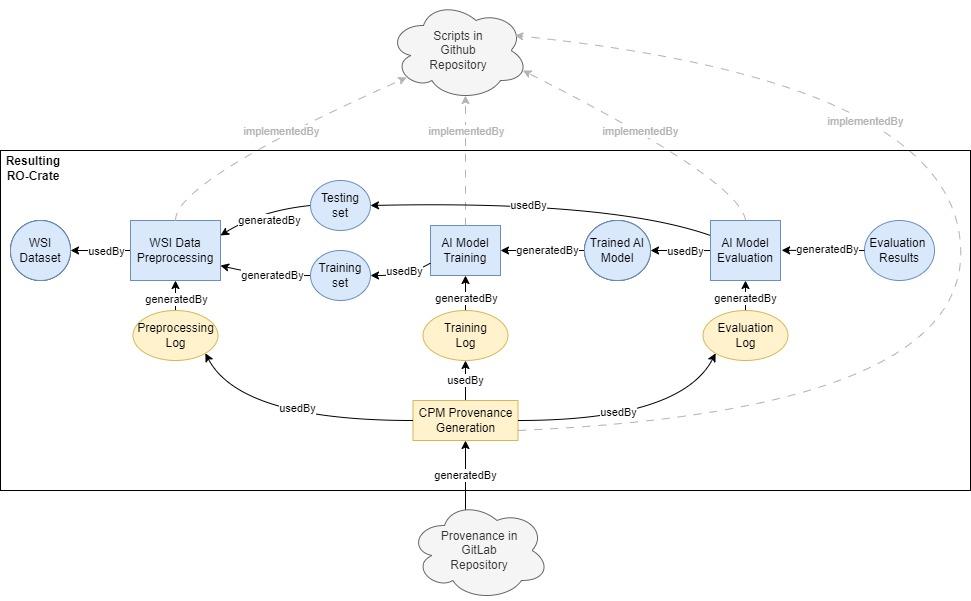
Figure 4: Schema of the resulting RO Crate.
The resulting RO-Crate is available in Zenodo repository12.
https://github.com/RationAI/crc_ml-provenance/blob/new-auto-provenance/Manuscript_supplementary/Distributed_Provenance_Model_supplementary.pdf↩︎
A placeholder is used instead of a specific URI because the CPM namespace has not been published yet. Publication of the ontology is planned in mid 2023 as part of an EOSC-Life project provenance deliverable. The expected URI is http://www.commonprovenancemodel.org/ns/↩︎
The bundle can not be published and changed subsequently. The bundle may be hashed or digitally signed, and the change would require recomputation of these values and publishing the updated content again.↩︎